Quel système RAG choisir pour votre application métier ?

Introduction : le RAG, colonne vertébrale de l’IA appliquée
Vous avez un catalogue produit de 50 000 références. Un employé tape une question dans votre chatbot interne : “Quel connecteur est compatible avec la série X400 en environnement humide ?”. Un LLM classique, même GPT-4o ou Claude, ne connaît pas votre catalogue. Il va produire une réponse plausible, mais fausse.
Le RAG (Retrieval-Augmented Generation) résout ce problème. Le principe : avant de laisser le LLM répondre, on va chercher les documents pertinents dans votre base de données, puis on les injecte dans le contexte du modèle. Le LLM génère sa réponse en s’appuyant sur vos données réelles, pas sur sa mémoire d’entraînement.
En 2026, le RAG est devenu incontournable parce que les cas d’usage se sont multipliés :
- Chatbot support client : réponses basées sur votre documentation, vos FAQ et vos tickets résolus ;
- Recherche documentaire interne : un juriste cherche un précédent dans 10 000 contrats ;
- Assistant RH : les employés posent des questions sur la convention collective, les congés ou la mutuelle ;
- Base de connaissances produit : des techniciens terrain cherchent une procédure de maintenance ;
- Analyse réglementaire : conformité RGPD, normes ISO, textes de loi.
Le point commun : vous avez des données propriétaires, et vous voulez qu’un LLM les exploite intelligemment. Pas besoin de fine-tuner un modèle à chaque mise à jour documentaire. Le RAG travaille sur vos données vivantes.
Mais entre Pinecone, pgvector, Qdrant, LangChain, Vertex AI et une dizaine d’autres options, le choix est devenu un labyrinthe. Ce guide est là pour vous aider à y voir clair.
Avant de choisir votre stack : l’audit data, le prérequis oublié
Avant de comparer les bases vectorielles ou de choisir un framework, il y a une étape que la majorité des projets RAG négligent. C’est la première cause d’échec.
Comme le souligne Jonas Roman, praticien RAG ayant livré plus de 60 projets en production : 70 a 80% du travail d’un projet RAG réside dans la préparation des données, pas dans les prompts, les modèles ou l’architecture. C’est le principe du garbage in, garbage out : aucune base vectorielle, aussi performante soit-elle, ne compensera des données mal préparées.
Avant de toucher au code, auditez vos données sur quatre dimensions :
- Qualité : les documents sont-ils lisibles ? Les PDF scannés sont-ils exploitables ? Pour les documents complexes, comme les schémas ou les tableaux, des outils d’OCR avancés comme Mistral OCR offrent de bien meilleurs résultats que les extracteurs basiques.
- Structure : vos données sont-elles homogènes ? Emails de 3 lignes mélangés à des rapports de 200 pages, formats incohérents, informations contradictoires entre documents : tout cela doit être cartographié en amont.
- Complétude : avez-vous réellement toute la donnée nécessaire ? Un écueil fréquent : les équipes métier affirment disposer de toute la donnée, mais personne n’a vérifié. A mi-projet, une part significative s’avère inutilisable.
- Accessibilité : où vivent les données ? Documents non structurés, bases SQL, ERP, CRM ? Cette cartographie détermine l’architecture cible.
Conseil : quelques heures de cadrage avec vos experts métier en amont peuvent éviter des semaines de développement dans la mauvaise direction. Investissez ce temps avant d’écrire la moindre ligne de code.
Quand le RAG n’est pas la réponse
Le réflexe “données internes = RAG vectoriel” est devenu automatique. Mais le RAG classique, c’est-à-dire embedding + recherche sémantique, n’est pas toujours le bon outil. Avant de foncer dans l’implémentation, posez-vous ces questions.
Est-ce que la réponse existe dans une base structurée ?
Si vous demandez “Quel a été le CA par région en 2023 ?” et que la donnée vit dans un ERP ou une base SQL, pas besoin de RAG. Une requête SQL directe sera plus fiable, plus rapide et moins chère. Le RAG retrouve des passages de texte : il n’agrège pas, il ne calcule pas, il ne garantit pas l’exactitude des chiffres.
Est-ce qu’il faut parcourir tout le corpus ?
“Quels sont les grands enseignements de nos 30 rapports d’audit 2024 ?” Le RAG est conçu pour trouver les passages les plus pertinents, pas pour lire un rayon entier. Pour ces analyses globales, privilégiez des approches map-reduce, qui résument chaque document puis synthétisent les résumés, ou du traitement multipass.
Avez-vous besoin d’exhaustivité ?
“Donne-moi tous les contrats contenant une clause de non-concurrence”. Sur 200 contrats, le RAG vectoriel peut en retrouver 40 sur 47. Les 7 restants passent entre les mailles du filet. En contexte juridique ou réglementaire, ce manque est inacceptable. Pour ces cas, vous avez besoin de Knowledge Graphs ou de recherche hybride renforcée.
Est-ce qu’il y a des calculs à faire ?
Le RAG ne sait pas calculer. Si la réponse nécessite des opérations arithmétiques sur les données, créez des tools dédiés, comme des fonctions de calcul ou des appels API, que le LLM peut déclencher en dehors du pipeline RAG.
Les bons systèmes sont presque toujours hybrides. Un LLM-classifier en amont analyse l’intention de la question et la route vers le bon outil : RAG vectoriel pour la compréhension sémantique, requêtes SQL pour les données structurées, tools pour les calculs, map-reduce pour les synthèses globales. Ce routeur est simplement un LLM placé en amont qui classifie la question en quelques secondes. Pas besoin d’une infrastructure complexe pour commencer.
Les briques du RAG : comprendre la chaîne complète
Un système RAG n’est pas un outil unique. C’est un pipeline composé de cinq étapes distinctes, chacune avec ses propres choix technologiques.
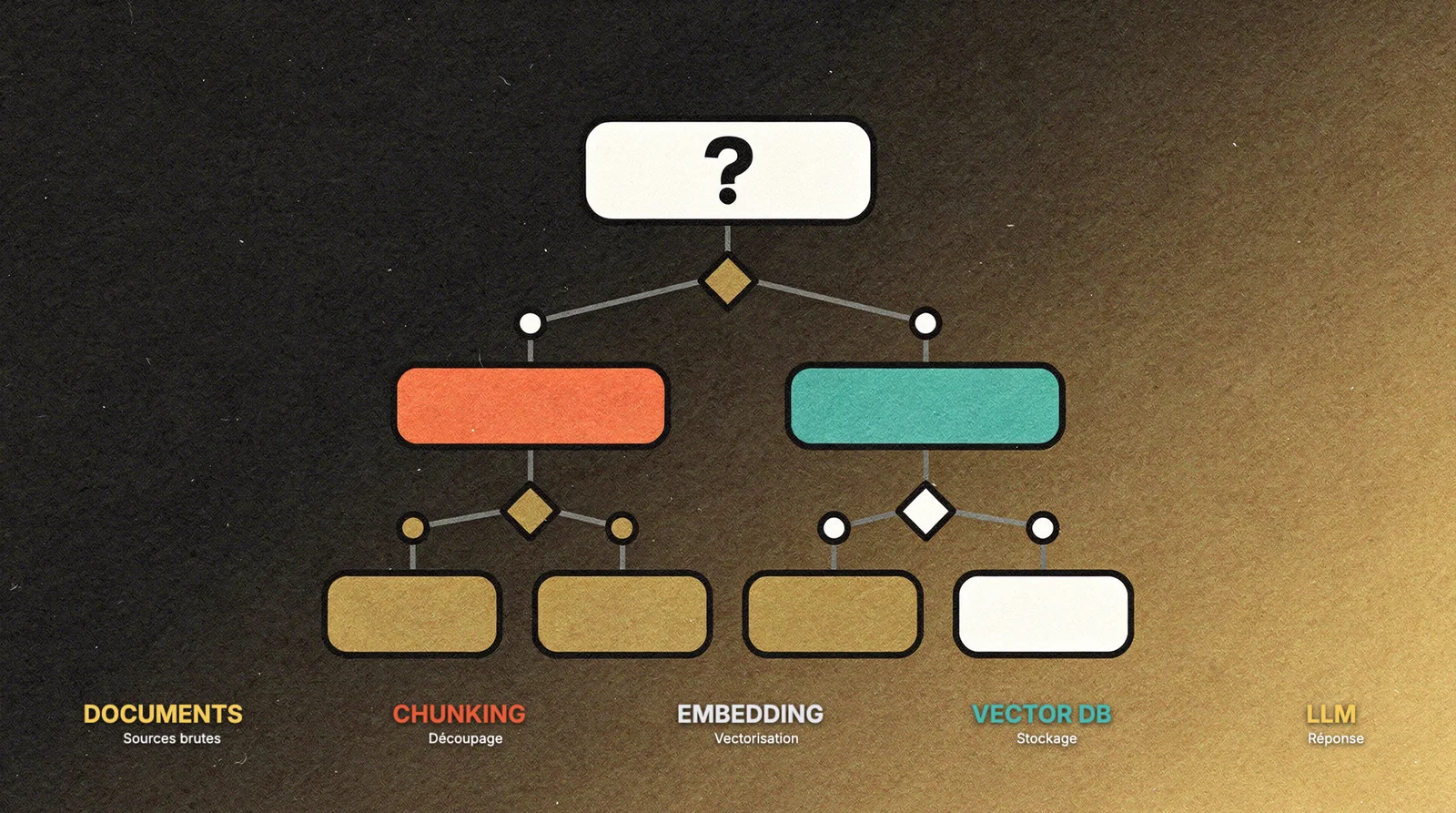
1. Ingestion
Vos documents bruts, qu’il s’agisse de PDF, pages web, emails, fichiers Word ou bases SQL, doivent être transformés en morceaux exploitables. C’est l’étape de parsing et de chunking.
- Parsing : extraire le texte d’un PDF scanné, interpréter un tableau HTML, nettoyer du Markdown ;
- Chunking : découper un document de 200 pages en segments de 500 à 1 500 tokens, avec ou sans chevauchement.
Le chunking est plus critique qu’on ne le pense. Des chunks trop gros diluent la pertinence. Trop petits, ils perdent le contexte. Il n’y a pas de taille universelle : cela dépend de vos documents et de vos requêtes.
Les 5 erreurs de chunking les plus coûteuses
- Couper au milieu d’un tableau : un tableau coupé en deux donne deux chunks incompréhensibles. Détectez les tableaux et gardez-les en un seul chunk.
- Overlap trop grand : un chevauchement de 50% entre chunks double le volume de votre index sans améliorer la qualité. Visez 10 a 15% d’overlap, pas plus.
- Perdre les métadonnées : le titre du chapitre, le nom du document, la date. Ces informations disparaissent souvent lors du chunking. Attachez-les systématiquement comme métadonnées du chunk.
- Ignorer la structure du document : chunker un document juridique par nombre de tokens ignore les articles et sections. Utilisez la structure logique comme délimiteur.
- Un seul format pour tous les documents : un email de 3 lignes et un rapport de 200 pages ne se chunkent pas pareil. Adaptez la stratégie au type de document.
Contextual Embedding : enrichir chaque chunk
Une technique émergente améliore significativement la qualité du retrieval : le contextual embedding. Le principe : avant de vectoriser un chunk, demandez à un LLM de générer une phrase de résumé qui situe le chunk dans le contexte global du document. Cette phrase est ajoutée au chunk avant l’embedding.
Résultat : chaque chunk “sait” d’où il vient. Un paragraphe sur les spécifications d’une pompe X400 ne sera plus un fragment orphelin. Il portera le contexte “extrait du manuel de maintenance de la pompe X400, chapitre étanchéité”. La surface de contact sémantique augmente, et le retrieval devient beaucoup plus précis.
2. Embedding
Chaque chunk est transformé en vecteur, c’est-à-dire une liste de nombres, typiquement 256 à 3 072 dimensions, qui encode le sens sémantique du texte. Deux phrases qui disent la même chose auront des vecteurs proches, même si les mots sont différents.
Les modèles d’embedding les plus utilisés en 2026 :
| Modèle | Dimensions | Editeur | Note |
|---|---|---|---|
text-embedding-3-small | 1 536 | OpenAI | Bon rapport qualité/prix, le plus répandu |
text-embedding-3-large | 3 072 | OpenAI | Plus précis, plus cher |
embed-v4 | 1 024 | Cohere | Excellent en multilingue |
voyage-3-large | 1 024 | Voyage AI | Très bon sur le code et les documents techniques |
voyage-multimodal-3 | 1 024 | Voyage AI | Embedding texte + images |
gemini-embedding-2 | 3 072 | Nouveau en mars 2026, nativement multimodal | |
mistral-embed | 1 024 | Mistral AI | Très économique, correct en retrieval général |
codestral-embed | 3 072 | Mistral AI | Spécialisé code |
nomic-embed-text-v2-moe | 768 | Nomic AI | Open-source, Mixture of Experts, bon rapport qualité/taille |
gte-qwen2-instruct | 768-8192 | Alibaba | Open-source, dimensions variables, très bon multilingue |
| BGE-M3, E5-Mistral, GTE | Variable | Communauté | Gratuits, à héberger soi-même |
A noter : Gemini Embedding 2, sorti en mars 2026, change la donne. C’est le premier modèle d’embedding capable de placer du texte, des images, de la vidéo, de l’audio et des PDF dans un même espace vectoriel. Concrètement, vous pouvez chercher “schéma de câblage du connecteur X400” et retrouver aussi bien un paragraphe de documentation qu’une photo du connecteur.
Il domine les benchmarks MTEB en anglais, multilingue et code, supporte plus de 100 langues, et propose le Matryoshka Learning pour tronquer les vecteurs sans perte significative. Seul bémol : il est encore en Public Preview et coûte environ 50% plus cher qu’OpenAI pour le texte seul. Pour un usage texte pur, les alternatives restent compétitives. Mais si vos documents contiennent des images ou des schémas, Gemini Embedding 2 n’a pas de concurrent direct.
Le choix du modèle d’embedding a un impact direct sur la qualité de la recherche. Un modèle multilingue sera meilleur si vos documents mélangent français et anglais. Un modèle spécialisé code performera mieux sur de la documentation technique.
3. Stockage vectoriel
Les vecteurs doivent être stockés dans une base capable de faire de la recherche par similarité. C’est le cœur du sujet et la section principale de cet article.
4. Retrieval
Quand un utilisateur pose une question, sa requête est aussi transformée en vecteur, puis comparée aux vecteurs stockés pour trouver les chunks les plus proches sémantiquement.
Mais la recherche vectorielle pure a ses limites. Les approches modernes combinent :
- Recherche sémantique : similarité vectorielle ;
- Recherche full-text : BM25, mots-clés exacts, indispensable pour les noms propres, codes produit et numéros de référence ;
- Recherche hybride : combinaison des deux, avec pondération ;
- Reranking : un modèle spécialisé, comme Cohere Rerank ou Jina Reranker, reclasse les résultats pour affiner la pertinence.
La recherche hybride est devenue le standard en production. La recherche vectorielle seule rate les requêtes contenant des identifiants précis, comme “facture No.2024-0847”, tandis que le full-text rate les requêtes formulées différemment du document source.
Comment fonctionne la recherche hybride concrètement ?
Le principe est simple : on exécute deux recherches en parallèle, vectorielle et BM25 full-text, puis on fusionne les résultats. La méthode de fusion la plus utilisée est le Reciprocal Rank Fusion :
- La recherche vectorielle retourne un classement : document A en premier, B en troisième, C en cinquième.
- La recherche BM25 retourne un autre classement : B en premier, D en deuxième, A en quatrième.
- Le RRF combine les deux en pondérant par l’inverse du rang, avec
kgénéralement autour de 60.
score = 1 / (k + rang_vectoriel) + 1 / (k + rang_bm25)Le document B, bien classé dans les deux recherches, remonte en tête.
L’avantage : si un utilisateur cherche “connecteur X400 résistant à l’humidité”, la recherche vectorielle capte le sens, par exemple “résistant à l’humidité” proche de “étanche” ou “IP67”, tandis que le BM25 attrape le terme exact “X400” que le vectoriel pourrait rater. En combinant les deux, vous obtenez le bon document même si la requête mélange langage naturel et termes techniques.

4.5. Prompt engineering : la brique invisible
Entre le retrieval et la génération, il y a une étape que beaucoup négligent : la construction du prompt. Passer 80% de son temps sur le retrieval et écrire un prompt basique, c’est la recette pour des hallucinations, même avec les bons documents en contexte.
Structurez votre prompt en blocs séparés :
- Système : le rôle de l’IA, par exemple expert technique, juriste ou support client.
- Instructions : les règles strictes, le format de réponse, la longueur, le ton, et surtout l’ancrage : “Réponds uniquement à partir des documents fournis. Si l’information n’est pas dans le contexte, dis-le explicitement.”
- Contexte : les chunks récupérés par le retrieval, avec leurs métadonnées.
- Question : la requête de l’utilisateur.
Trois techniques qui changent tout :
- Citation obligatoire : imposez au LLM de citer ses sources pour chaque affirmation. Cela réduit les hallucinations et permet la vérification humaine. En contexte réglementaire ou juridique, un système incapable de justifier ses réponses ne sera pas adopté.
- Few-shot examples : fournissez 2 ou 3 exemples complets de question, raisonnement et réponse attendue. Le LLM reproduira ce schéma.
- Gestion du “lost in the middle” : les LLM ont tendance à ignorer les informations situées au milieu d’un long contexte. Placez les chunks les plus pertinents en début et en fin de contexte, pas au milieu.
5. Génération
Les chunks retrouvés sont injectés dans le prompt du LLM, qui génère la réponse finale. Le choix du LLM, GPT-4o, Claude, Gemini, Llama ou Mistral, affecte la qualité de la synthèse, mais c’est généralement la partie la plus simple à changer.
Les bases vectorielles : le comparatif détaillé

C’est ici que se joue la décision architecturale la plus structurante. Trois grandes familles existent.
Bases spécialisées
Ces outils sont conçus dès le départ pour le stockage et la recherche vectorielle.
Pinecone
- Déploiement : 100% managé, serverless.
- Forces : mise en place en 5 minutes, pas d’infrastructure à gérer, scaling automatique, recherche hybride native, namespaces pour le multi-tenant.
- Faiblesses : propriétaire, vendor lock-in, coûteux à l’échelle, pas d’auto-hébergement possible, latence variable sur le plan serverless.
- Pricing : gratuit jusqu’à 2 Go, puis stockage et lectures facturés.
- Cas idéal : équipes qui veulent du RAG en production sans ops, scale-ups qui valorisent le time-to-market.
- Echelle : milliards de vecteurs.
Qdrant
- Déploiement : self-hosted ou Qdrant Cloud.
- Forces : écrit en Rust, performant, filtrage avancé sur les métadonnées, recherche hybride, quantification intégrée, API simple.
- Faiblesses : le self-hosted demande du DevOps, la version cloud est plus récente que Pinecone.
- Pricing : open-source en self-hosted, cloud à partir d’environ $25/mois.
- Cas idéal : équipes techniques qui veulent le contrôle sans sacrifier la performance, multi-cloud ou on-premise.
- Echelle : testé sur des milliards de vecteurs, sharding horizontal.
Weaviate
- Déploiement : self-hosted ou Weaviate Cloud.
- Forces : API GraphQL native, vectorisation intégrée, recherche hybride BM25 + vectorielle, modules de generative search, bon écosystème.
- Faiblesses : plus lourd que Qdrant en ressources, courbe d’apprentissage GraphQL, couplage possible avec la vectorisation intégrée.
- Pricing : open-source, cloud à partir d’environ $25/mois.
- Cas idéal : projets qui veulent un pipeline RAG intégré dans la base.
- Echelle : bonne, mais moins éprouvée que Pinecone ou Qdrant sur les très gros volumes.
Milvus / Zilliz
- Déploiement : self-hosted avec Milvus ou managé avec Zilliz Cloud.
- Forces : conçu pour le scale massif, séparation stockage/calcul, GPU acceleration, nombreux types d’index, projet CNCF.
- Faiblesses : complexe à opérer, dépend de plusieurs composants, overkill pour les petits volumes.
- Pricing : open-source, Zilliz Cloud avec offre gratuite puis facturation à l’usage.
- Cas idéal : très gros volumes, équipes DevOps, recherche multimodale.
- Echelle : référence pour le scale massif.
ChromaDB
- Déploiement : embarqué en Python ou serveur.
- Forces : installation simple, API très accessible, parfait pour le prototypage et les notebooks.
- Faiblesses : pas conçu pour la production à grande échelle, pas de recherche hybride native, pas de haute disponibilité.
- Pricing : open-source, gratuit.
- Cas idéal : prototypage, POC, projets personnels.
- Echelle : quelques millions de vecteurs au maximum.
Turbopuffer
- Déploiement : serverless managé.
- Forces : stocke les vecteurs sur object storage, coût très bas au repos, BM25 natif, bon pour les workloads variables.
- Faiblesses : jeune, latence potentiellement plus élevée que les bases en mémoire, écosystème encore petit.
- Pricing : pay-per-use, compétitif pour les gros volumes peu requêtés.
- Cas idéal : gros corpus rarement requêtés, archivage sémantique, budget serré.
- Echelle : bonne sur le stockage, à valider sur les requêtes intensives.
Extensions de bases existantes
Vous avez déjà une base de données ? Ajoutez-lui des capacités vectorielles.
pgvector (PostgreSQL)
- Déploiement : extension PostgreSQL disponible sur Supabase, Neon, AWS Aurora, Railway ou tout PostgreSQL auto-hébergé.
- Forces : pas de nouvelle base à gérer, vecteurs à côté des données relationnelles, SQL standard, jointures avec les tables métier, recherche hybride via
tsvector+ pgvector. - Faiblesses : performances inférieures aux bases spécialisées au-delà de 10M vecteurs, indexation HNSW gourmande en RAM.
- Pricing : extension open-source, coût de votre PostgreSQL.
- Cas idéal : PME déjà sur PostgreSQL, projets où les données vectorielles doivent être jointes aux données métier.
- Echelle : confortable jusqu’à 5-10M vecteurs.
Exemple : recherche sémantique avec pgvector
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title TEXT,
content TEXT,
embedding vector(1536)
);
CREATE INDEX ON documents
USING hnsw (embedding vector_cosine_ops);
SELECT title, content,
1 - (embedding <=> $1) AS similarity
FROM documents
ORDER BY embedding <=> $1
LIMIT 5;MongoDB Atlas Vector Search
- Déploiement : intégré à MongoDB Atlas.
- Forces : transparent si vous êtes déjà sur MongoDB, recherche vectorielle + filtrage sur documents, pipeline d’agrégation unifié.
- Faiblesses : uniquement sur Atlas, performances vectorielles moyennes comparées aux bases spécialisées.
- Cas idéal : applications déjà sur MongoDB Atlas.
Redis Vector Search
- Déploiement : Redis Stack ou Redis Cloud.
- Forces : très rapide, recherche hybride avec RediSearch, bon pour le cache sémantique.
- Faiblesses : coûteux en RAM pour les gros volumes, persistence moins robuste qu’un PostgreSQL.
- Cas idéal : cache sémantique, RAG temps réel à faible latence.
Cloudflare Vectorize
- Déploiement : managé, intégré à Cloudflare Workers.
- Forces : intégration native avec Workers AI, déploiement global edge, pas de serveur à gérer.
- Faiblesses : fonctionnalités limitées comparées aux bases spécialisées, verrouillé dans l’écosystème Cloudflare.
- Cas idéal : applications déjà sur Cloudflare Workers.
Turso Vector (SQLite)
- Déploiement : managé avec Turso ou libSQL local.
- Forces : SQLite distribué avec support vectoriel, léger, réplication edge.
- Faiblesses : fonctionnalités vectorielles encore basiques, communauté plus petite.
- Cas idéal : applications edge, embarquées ou mobiles avec RAG local.
Intégrées à une plateforme
Ces solutions couplent le stockage vectoriel à un écosystème plus large.
Convex (@convex-dev/rag)
- Déploiement : managé, intégré à Convex.
- Forces : vectoriel natif dans une base temps réel, pas de service séparé, embeddings et recherche via fonctions Convex, réactivité temps réel, recherche hybride, TypeScript end-to-end.
- Faiblesses : couplé à Convex, moins de contrôle sur l’indexation que Qdrant ou Milvus.
- Pricing : inclus dans Convex.
- Cas idéal : applications temps réel qui ont besoin de RAG sans complexité d’infrastructure.
- Echelle : adaptée aux PME et scale-ups.
Exemple : recherche sémantique avec Convex RAG
await rag.insertDocument(ctx, {
title: "Procédure de maintenance pompe X400",
body: "Pour l'entretien trimestriel de la pompe X400...",
metadata: { category: "maintenance", equipmentId: "X400" },
});
const results = await rag.search(ctx, {
query: "entretien pompe environnement humide",
limit: 5,
filter: { category: "maintenance" },
});Firebase / Vertex AI RAG Engine
- Déploiement : managé sur Google Cloud.
- Forces : pipeline RAG complet géré par Google, intégration native avec Gemini, grounding avec Google Search.
- Faiblesses : vendor lock-in Google Cloud, pricing complexe, documentation dense.
- Cas idéal : entreprises déjà sur Google Cloud, projets qui veulent du grounding avec Google Search.
OpenAI File Search
- Déploiement : managé par OpenAI.
- Forces : upload de fichiers, RAG fonctionnel en quelques lignes, chunking et embedding automatiques.
- Faiblesses : boîte noire, peu de contrôle sur le chunking, l’embedding ou le retrieval, limité aux modèles OpenAI, coûteux pour les gros volumes.
- Cas idéal : prototypage très rapide, applications simples.
Les frameworks RAG : la couche orchestration
Le stockage vectoriel est nécessaire mais pas suffisant. En production, vous avez besoin d’orchestrer le pipeline : connecter l’ingestion, gérer le chunking, chaîner la recherche et la génération, gérer les erreurs, le streaming et le multi-tour.
LangChain / LangGraph
- Ce que c’est : le framework RAG le plus populaire, en Python et JavaScript.
- Forces : écosystème immense, connecteurs pour toutes les bases vectorielles et tous les LLM, communauté active, LangSmith pour le monitoring.
- Faiblesses : abstraction parfois excessive, debug difficile, API instable, overhead de performance pour les cas simples.
- Verdict : bon pour démarrer et prototyper. En production, beaucoup d’équipes finissent par n’utiliser que quelques modules.
LlamaIndex
- Ce que c’est : framework spécialisé dans l’indexation et le retrieval de documents.
- Forces : très bon sur l’ingestion de documents complexes, abstractions de retriever bien pensées, moins de sur-abstraction que LangChain.
- Faiblesses : moins polyvalent que LangChain hors RAG, communauté plus petite.
- Verdict : excellent si votre problème principal est l’ingestion de documents complexes.
Haystack
- Ce que c’est : framework RAG orienté production avec pipelines déclaratifs.
- Forces : pipelines explicites, bon support des évaluations, expertise NLP solide.
- Faiblesses : communauté plus petite, principalement Python.
- Verdict : solide pour la production.
RAGatouille
- Ce que c’est : bibliothèque légère centrée sur ColBERT.
- Forces : retrieval de haute qualité, simple d’utilisation, pas besoin de base vectorielle séparée.
- Faiblesses : niche, pas un framework complet, performance production à valider.
- Verdict : intéressant pour améliorer la qualité du retrieval sans changer toute l’architecture.
Vercel AI SDK
- Ce que c’est : SDK TypeScript/JavaScript pour construire des applications IA, avec support RAG intégré.
- Forces : pensé pour React, Next.js et le streaming, API élégante, agnostique sur le LLM et la base vectorielle.
- Faiblesses : écosystème JavaScript uniquement, moins de connecteurs natifs que LangChain.
- Verdict : très bon choix pour les équipes TypeScript/React.
Solutions clé-en-main
Vertex AI RAG Engine et OpenAI File Search gèrent le pipeline pour vous : upload, indexation, requête, réponse. Le time-to-market est imbattable, mais le contrôle est faible, le vendor lock-in fort, et le coût peut exploser.
Google Vertex AI & Grounding : l’approche Google
Google a pris une direction distincte qui mérite une section dédiée.
Vertex AI Search
Le grounding permet à Gemini de vérifier ses réponses contre le web en temps réel. Quand Gemini génère une réponse, il peut interroger Google Search pour confirmer les faits et ajouter des citations.
C’est utile lorsque vos données propriétaires doivent être complétées par des informations publiques à jour : actualités, réglementation, données de marché.
Vertex AI RAG Engine
Un pipeline RAG complet managé :
- Vous créez un corpus et uploadez vos documents.
- Google gère le parsing, le chunking, l’embedding et l’indexation.
- Vous requêtez via l’API ou directement depuis Gemini.
La promesse : zéro infrastructure vectorielle à gérer. La réalité : c’est efficace pour les cas standards, mais le manque de contrôle sur le chunking et le retrieval peut devenir frustrant pour des cas métier complexes.
Quand choisir l’approche Google ?
- Vous êtes déjà sur Google Cloud.
- Vous utilisez Gemini comme LLM principal.
- Vos documents sont relativement standards.
- Vous voulez un time-to-market minimal.
Quand construire vous-même ?
- Vous avez besoin de contrôle fin sur le chunking.
- Vous voulez être agnostique sur le LLM.
- Vous avez des contraintes de latence strictes.
- Vous voulez contrôler précisément la recherche hybride.
Aller plus loin : les aspects souvent négligés
Evaluer la qualité de votre RAG
Choisir une stack est une chose. Savoir si elle fonctionne bien en est une autre. En production, vous devez mesurer la qualité des réponses, pas juste espérer qu’elles soient bonnes.
Des frameworks d’évaluation automatique permettent de quantifier la performance :
- RAGAS : mesure la fidélité, la pertinence et la complétude.
- DeepEval : ajoute des métriques comme hallucination, toxicité et biais, avec intégration pytest.
- Haystack Evaluation : utile si vous utilisez déjà Haystack.
Le Golden Dataset : votre outil de mesure numéro 1
Les frameworks d’évaluation ne servent à rien sans données de référence. Le Golden Dataset est un échantillon de questions réelles posées par vos utilisateurs, associées aux réponses exactes attendues et aux documents sources. C’est l’outil le plus sous-estimé et pourtant le plus déterminant de tout projet RAG.
Comment le construire :
- Travaillez avec vos experts métier, jamais seul. Sinon, vous créez un biais de confirmation.
- Collectez des questions réelles réparties sur trois niveaux de difficulté : facile, moyen, complexe.
- Pour chaque question, définissez la réponse attendue et le format de sortie.
- Pour un prototype, 10 à 50 questions suffisent. Pour la production, visez 100 à 500 questions.
Les trois métriques à surveiller :
- Précision : le LLM fournit-il une réponse exacte, complète et reproductible ?
- Recall : le retrieval retrouve-t-il les bons chunks ?
- Faithfulness : la réponse est-elle fidèle aux sources, sans hallucination ?
- Latence : au-delà de 3 à 5 secondes, l’utilisateur décroche.
Règle critique : modifiez une seule variable à la fois, puis rejouez le Golden Dataset. C’est la seule façon de savoir ce qui améliore ou dégrade la qualité.
Le RAG multimodal : au-delà du texte
En 2026, les entreprises ne cherchent plus seulement dans du texte. Les techniciens veulent interroger des schémas techniques, les analystes veulent comprendre des graphiques financiers, les équipes formation veulent indexer des vidéos.
Le RAG multimodal est encore jeune, mais plusieurs approches émergent :
- ColPali / ColQwen : modèles de retrieval qui travaillent directement sur les images de pages, sans OCR.
- Milvus / Zilliz : support natif des vecteurs multimodaux.
- LLM multimodaux : GPT-4o, Gemini et Claude peuvent analyser des images en contexte RAG, mais le retrieval d’images pertinentes reste le défi.
Si vos documents métier contiennent beaucoup de visuels, le multimodal n’est plus un luxe. Mais attendez-vous à un pipeline plus complexe et des coûts d’embedding plus élevés.
Confidentialité et données sensibles
Pour les entreprises soumises au RGPD ou manipulant des données sensibles, l’ingestion doit inclure une brique de détection et d’anonymisation des données personnelles avant l’embedding.
Concrètement :
- Avant l’embedding : scanner les chunks pour détecter noms, emails, téléphones, IBAN ou numéros sensibles.
- Anonymiser ou pseudonymiser : remplacer les PII par des tokens génériques avant de créer les vecteurs.
- Outils : Microsoft Presidio, AWS Comprehend, spaCy avec modèles NER custom.
Un vecteur d’embedding contient une représentation sémantique du texte. Il est théoriquement possible d’en extraire des informations sensibles. L’anonymisation en amont reste la protection la plus fiable.
L’interface utilisateur : la brique oubliée
La quasi-totalité des guides RAG s’arrêtent au pipeline technique. Pourtant, c’est l’interface qui détermine l’adoption.
Le chatbot classique est un piège. Une barre de texte vide avec “Posez votre question…” semble intuitive. En pratique, l’utilisateur ne sait pas toujours quoi demander, comment formuler sa requête ni quel contexte fournir. Résultat : questions vagues, réponses imprécises, perte de confiance, abandon.
L’alternative : des interfaces métier guidées. Au lieu d’une barre de texte, proposez des menus déroulants, des champs structurés, des boutons de sélection. L’interface capture 4 ou 5 points de contexte précis et les structure en JSON avant d’envoyer la requête au pipeline. En sortie, le LLM restitue l’information dans un format structuré : symptômes, causes, solutions, sources.
Pourquoi ça marche :
- Réduction de la charge cognitive : l’utilisateur n’a pas à deviner la bonne formulation.
- Meilleur retrieval : une requête structurée avec du contexte métier a une surface sémantique plus large.
- Orchestration par l’UI : selon les choix de l’utilisateur, l’interface peut router vers RAG, SQL ou calcul.
- Adoption : la qualité perçue d’un RAG dépend autant de son interface que de son pipeline.
Retour d’expérience : Jonas Roman observe que la grande majorité de ses projets RAG performants en production n’utilisent pas de chatbot, mais des interfaces métier dédiées, plus rapides à prendre en main et mieux adaptées au quotidien des employés.
Observabilité : savoir pourquoi ça marche
Evaluer un RAG avant le déploiement est nécessaire. Mais en production, vous avez besoin de monitoring continu.
Placez des points de contrôle à chaque étape critique :
- Après le retrieval : quels chunks ont été remontés ? Sont-ils pertinents ?
- Après le reranking : l’ordre a-t-il changé ? Les bons documents sont-ils en tête ?
- A la réponse finale : la réponse cite-t-elle ses sources ? Est-elle fidèle au contexte ?
Quand une réponse est mauvaise, ces checkpoints permettent de faire du reverse engineering : est-ce que le retrieval a remonté les mauvais documents ? Le bon document était-il dans le contexte mais le LLM l’a ignoré ? Le prompt était-il mal structuré ?
Rejetez les boîtes noires pour les cas sérieux. Les solutions RAG as a Service sont pratiques pour prototyper, mais vous n’avez aucune visibilité sur ce qui se passe à l’intérieur. En finance, santé ou juridique, l’explicabilité n’est pas un bonus : c’est une condition d’existence.
Au-delà du vectoriel : les nouvelles approches RAG
Le RAG ne se résume pas à “embedding + base vectorielle”. Plusieurs approches émergentes complètent ou remplacent la recherche sémantique classique.
GraphRAG / Knowledge Graphs
Au lieu de découper le texte en chunks et de les vectoriser indépendamment, le GraphRAG conserve les relations et les liens logiques entre les informations. C’est particulièrement puissant quand vous avez besoin d’exhaustivité : trouver tous les contrats avec une clause spécifique, tracer toutes les dépendances d’un processus, identifier toutes les non-conformités dans un corpus réglementaire.
Page Indexing
Technique de RAG sans recherche vectorielle qui indexe les documents par pages et par structure logique plutôt que par vecteurs. Utile quand la structure du document porte autant de sens que son contenu.
Agents File Search explorateurs
Des agents utilisent le multi-tour pour lire directement dans les corpus de données, comme le ferait un humain. Ils posent une première requête, analysent les résultats, affinent leur recherche et itèrent jusqu’à trouver l’information.
Self-RAG / Reflective RAG
Le système lance une recherche, puis vérifie lui-même si les informations récupérées sont pertinentes et suffisantes. Si le seuil de qualité n’est pas atteint, il relance de nouvelles requêtes, affine son approche, et ne livre la réponse qu’après avoir passé ses propres critères.
Ces approches restent souvent en phase de R&D. Elles sont à surveiller, mais à prendre avec prudence avant une mise en production. Le RAG vectoriel classique avec recherche hybride reste le standard éprouvé.
Matrice de décision
| Solution | Complexité | Coût | Scalabilité | Latence | Hybride | Multi-tenant | Open-source | Maturité |
|---|---|---|---|---|---|---|---|---|
| Pinecone | Faible | Elevé | 5/5 | 4/5 | Oui | Oui | Non | 5/5 |
| Qdrant | Moyen | Faible à moyen | 5/5 | 5/5 | Oui | Oui | Oui | 4/5 |
| Weaviate | Moyen | Faible à moyen | 4/5 | 4/5 | Oui | Oui | Oui | 4/5 |
| Milvus | Elevé | Faible à moyen | 5/5 | 5/5 | Oui | Oui | Oui | 4/5 |
| ChromaDB | Faible | Gratuit | 2/5 | 3/5 | Non | Non | Oui | 2/5 |
| Turbopuffer | Faible | Faible | 4/5 | 3/5 | Oui | Oui | Non | 2/5 |
| pgvector | Faible | Faible | 3/5 | 3/5 | Manuel | Oui | Oui | 4/5 |
| MongoDB Atlas VS | Faible | Moyen | 4/5 | 3/5 | Non | Oui | Non | 3/5 |
| Redis VS | Moyen | Moyen | 3/5 | 5/5 | Oui | Oui | Oui | 3/5 |
| Convex RAG | Faible | Faible à moyen | 3/5 | 4/5 | Oui | Oui | SDK oui | 3/5 |
| Vertex AI RAG | Faible | Moyen à élevé | 5/5 | 3/5 | Oui | Oui | Non | 3/5 |
| OpenAI File Search | Faible | Elevé | 3/5 | 3/5 | Non | Non | Non | 3/5 |
Recommandations par profil
Startup early-stage
-> Convex (@convex-dev/rag) ou pgvector via Supabase
Vous n’avez pas de DevOps, vous voulez un produit en ligne rapidement. Convex vous donne une base de données, du vectoriel et du temps réel dans un seul service. Supabase + pgvector est l’alternative si vous préférez PostgreSQL et que vos besoins vectoriels sont simples.
Ne dépensez pas 3 mois à architecturer le système RAG parfait. Commencez simple, itérez.
PME avec PostgreSQL existant
-> pgvector
Vous avez déjà PostgreSQL en production, une équipe qui le connaît, des backups en place. Ajoutez l’extension pgvector : c’est une migration SQL. Vos vecteurs vivent à côté de vos données métier.
Limite : si vous dépassez 5 à 10 millions de vecteurs ou si la latence devient critique, il sera temps de migrer vers une base spécialisée.
Scale-up / gros volume
-> Pinecone ou Qdrant
Vous avez des dizaines de millions de documents, du trafic soutenu, des exigences de latence. Pinecone si vous voulez zéro ops. Qdrant si vous voulez le contrôle et que vous avez l’équipe pour l’opérer, ou Qdrant Cloud.
Enterprise Google Cloud
-> Vertex AI RAG Engine + Qdrant/Pinecone pour les cas avancés
Vertex AI pour les cas standards. Qdrant ou Pinecone pour les cas qui nécessitent un contrôle fin. Le grounding Google Search est un vrai différenciateur si vos utilisateurs ont besoin d’informations publiques à jour.
Enterprise multi-cloud
-> Qdrant ou Weaviate self-hosted
Vous ne voulez pas de vendor lock-in. Qdrant ou Weaviate tournent sur n’importe quel Kubernetes. Vous gardez le contrôle total sur vos données et votre infrastructure.
Prototype rapide
-> ChromaDB ou OpenAI File Search
Vous voulez valider une idée en un après-midi. ChromaDB si vous êtes en Python et voulez comprendre les mécanismes. OpenAI File Search si vous voulez juste voir le RAG fonctionner sans vous occuper des vecteurs.
Ne mettez ni l’un ni l’autre en production à grande échelle.
Conclusion : le RAG n’est pas un choix unique
Le RAG n’est pas un produit qu’on achète. C’est un spectre architectural qui va de “3 lignes de code avec OpenAI File Search” à “pipeline distribué avec Qdrant, reranking Cohere et évaluation continue”.
Le bon choix dépend de trois facteurs :
- Où vous en êtes : prototype, MVP, production établie ?
- Ce que vous avez : une équipe DevOps, PostgreSQL en place, Google Cloud ?
- Ce dont vous avez besoin : quel volume, quelle latence, quelle précision ?
La pire erreur est de sur-architecturer. Les architectures RAG multi-agents complexes peuvent sembler séduisantes, mais l’expérience terrain montre que la majorité des systèmes trop ambitieux ne tiennent pas en production. Chaque appel LLM supplémentaire multiplie le taux d’erreur. Si un modèle a 5% de taux d’erreur, empiler plusieurs appels en cascade fait chuter la fiabilité globale.
Commencez avec la solution la plus simple qui répond à votre besoin immédiat. pgvector ou Convex pour un premier RAG en production. ChromaDB pour un POC. Et migrez quand, et seulement quand, vous atteignez les limites.
La deuxième pire erreur est de sous-estimer le travail en amont. La base vectorielle la plus performante du monde ne compensera pas des données mal préparées, un chunking inadapté ou un modèle d’embedding mal choisi. La préparation des données et l’ingénierie métier représentent l’essentiel de l’effort.
La troisième erreur, souvent invisible : négliger l’interface. Un RAG techniquement solide derrière une simple barre de texte sera sous-utilisé. Pensez votre RAG comme un produit destiné à des utilisateurs métier, pas uniquement comme un pipeline technique.
Un mot sur les tendances : gardez un œil sur les architectures à stockage objet comme Turbopuffer, le GraphRAG pour les cas nécessitant exhaustivité et traçabilité des relations, et le Self-RAG qui promet de fiabiliser les architectures agentiques. Le RAG n’est pas en voie de disparition. Il évolue vers une infrastructure de connaissance centrale pour l’IA en entreprise.
Besoin d’aide pour choisir ? Chez AppExpress, nous implémentons des systèmes RAG pour les PME, du POC en une semaine au pipeline de production avec évaluation continue. Si vous hésitez entre les options ou si vous voulez valider votre architecture avant de vous engager, parlons-en.