¿Qué sistema RAG elegir para tu aplicación de negocio?

Introducción: RAG como columna vertebral de la IA aplicada
Tienes un catálogo de producto con 50.000 referencias. Un empleado escribe una pregunta en el chatbot interno: “¿Qué conector es compatible con la serie X400 en un entorno húmedo?” Un LLM clásico, incluso GPT-4o o Claude, no conoce tu catálogo. Generará una respuesta plausible, pero falsa.
El RAG (Retrieval-Augmented Generation) resuelve ese problema. El principio es sencillo: antes de dejar que el LLM responda, el sistema busca los documentos pertinentes en tus datos y los inyecta en el contexto del modelo. El LLM responde apoyándose en tus datos reales, no en su memoria de entrenamiento.
En 2026, RAG se ha vuelto imprescindible porque los casos de uso se han multiplicado:
- Chatbot de soporte al cliente: respuestas basadas en documentación, FAQ y tickets resueltos;
- Búsqueda documental interna: un equipo jurídico busca un precedente en 10.000 contratos;
- Asistente de RR. HH.: los empleados preguntan por vacaciones, beneficios o convenio colectivo;
- Base de conocimiento de producto: técnicos de campo buscan un procedimiento de mantenimiento;
- Análisis regulatorio: RGPD, normas ISO, textos legales.
El punto común es claro: tienes datos propietarios y quieres que un LLM los use de forma inteligente. No necesitas hacer fine-tuning del modelo cada vez que cambia un documento. RAG trabaja sobre datos vivos.
Pero entre Pinecone, pgvector, Qdrant, LangChain, Vertex AI y muchas otras opciones, la decisión se ha vuelto confusa. Esta guía ayuda a entender los compromisos.
Antes de elegir una stack: la auditoría de datos olvidada
Antes de comparar bases vectoriales o elegir un framework, hay una etapa que la mayoría de proyectos RAG omite. También es la primera causa de fracaso.
Como explica Jonas Roman, profesional RAG con más de 60 proyectos en producción: entre el 70 y el 80% del trabajo de un proyecto RAG está en la preparación de datos, no en prompts, modelos o arquitectura. Es el clásico garbage in, garbage out. Ninguna base vectorial, por potente que sea, compensa datos mal preparados.
Antes de escribir código, audita tus datos en cuatro dimensiones:
- Calidad: ¿los documentos son legibles? ¿Los PDF escaneados son explotables? Para documentos complejos, como diagramas o tablas, herramientas OCR avanzadas como Mistral OCR dan mejores resultados que extractores básicos.
- Estructura: ¿los datos son homogéneos? Emails de tres líneas mezclados con informes de 200 páginas, formatos incoherentes e información contradictoria deben mapearse desde el inicio.
- Completitud: ¿realmente tienes todos los datos necesarios? Es frecuente que los equipos de negocio crean tenerlo todo, pero nadie lo haya verificado. A mitad del proyecto, una parte importante puede resultar inutilizable.
- Accesibilidad: ¿dónde viven los datos? Documentos no estructurados, bases SQL, ERP, CRM. Este mapa determina la arquitectura objetivo.
Consejo práctico: unas horas de encuadre con expertos de negocio pueden ahorrar semanas de desarrollo en la dirección equivocada. Invierte ese tiempo antes de escribir la primera línea de código.
Cuándo RAG no es la respuesta
El reflejo “datos internos = RAG vectorial” se ha vuelto automático. Pero el RAG clásico, es decir embeddings más búsqueda semántica, no siempre es la herramienta correcta. Antes de implementarlo, hazte estas preguntas.
¿La respuesta ya existe en datos estructurados?
Si la pregunta es “¿Cuál fue la facturación por región en 2023?” y el dato vive en un ERP o una base SQL, no necesitas RAG. Una consulta SQL directa será más fiable, rápida y barata. RAG recupera pasajes de texto; no agrega, no calcula y no garantiza la exactitud de cifras.
¿Hay que recorrer todo el corpus?
“¿Cuáles son las grandes conclusiones de nuestros 30 informes de auditoría de 2024?” RAG está diseñado para encontrar los pasajes más pertinentes, no para leer una biblioteca completa. Para análisis globales, usa enfoques map-reduce, resumiendo cada documento y luego sintetizando los resúmenes, o un procesamiento multipass.
¿Necesitas exhaustividad?
“Dame todos los contratos que contienen una cláusula de no competencia.” En 200 contratos, un RAG vectorial puede encontrar 40 de 47. Los 7 restantes se pierden. En contextos jurídicos o regulatorios, ese hueco es inaceptable. Para estos casos necesitas Knowledge Graphs o búsqueda híbrida reforzada.
¿Hay cálculos que hacer?
RAG no calcula. Si la respuesta exige operaciones aritméticas sobre datos, crea tools dedicadas, como funciones de cálculo o llamadas API, que el LLM pueda activar fuera del pipeline RAG.
Los buenos sistemas son casi siempre híbridos. Un clasificador LLM aguas arriba analiza la intención y enruta la solicitud hacia la herramienta adecuada: RAG vectorial para comprensión semántica, SQL para datos estructurados, tools para cálculos, map-reduce para síntesis globales. Ese router puede ser simplemente un LLM que clasifica la pregunta en pocos segundos.
Las piezas de RAG
Un sistema RAG no es una herramienta única. Es un pipeline compuesto por cinco etapas, cada una con sus propias decisiones tecnológicas.
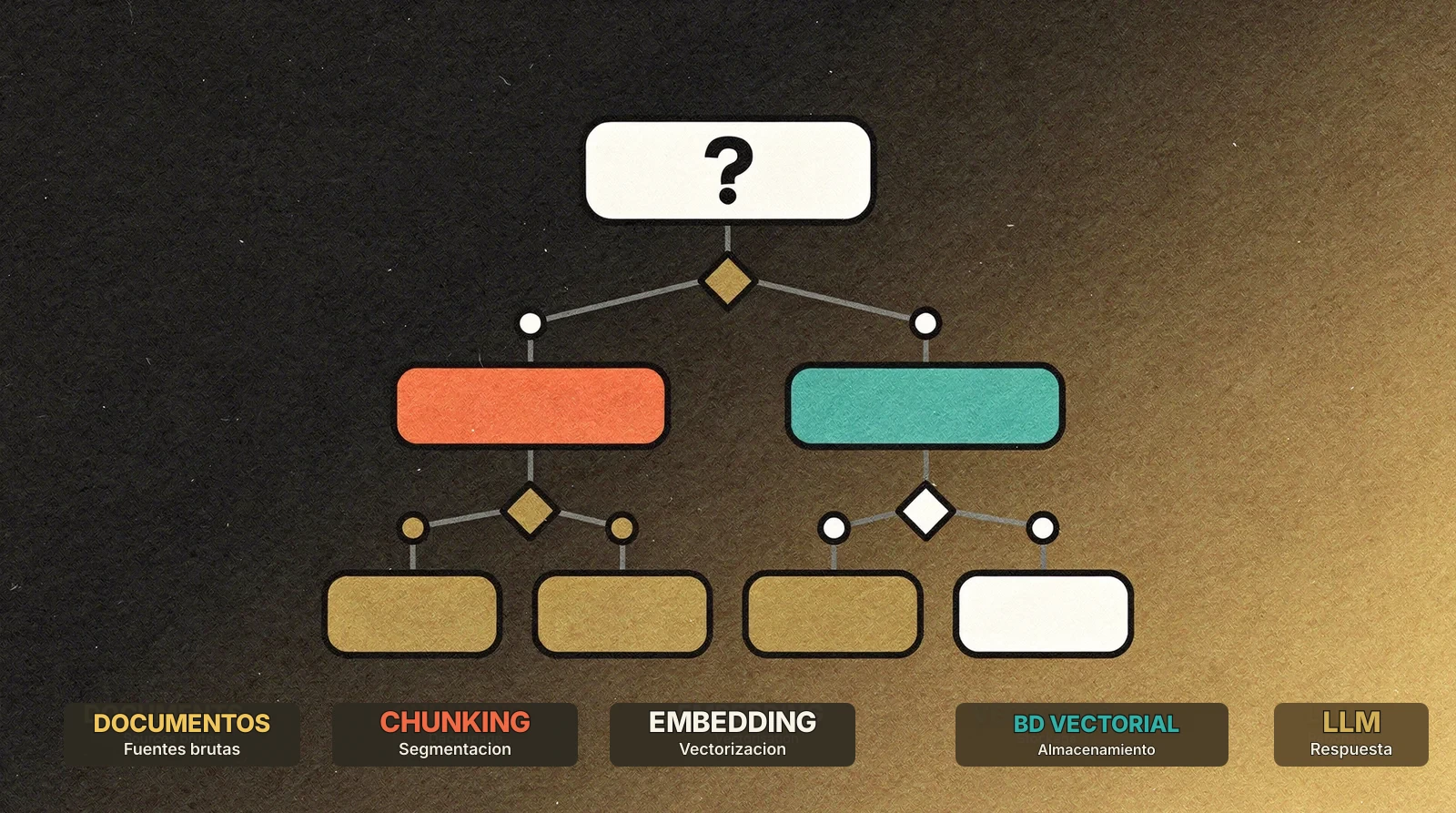
1. Ingesta
Los documentos brutos, ya sean PDF, páginas web, emails, archivos Word o datos SQL, deben transformarse en piezas utilizables. Es la etapa de parsing y chunking.
- Parsing: extraer texto de un PDF escaneado, interpretar una tabla HTML, limpiar Markdown;
- Chunking: dividir un documento de 200 páginas en segmentos de 500 a 1.500 tokens, con o sin solapamiento.
El chunking es más crítico de lo que parece. Chunks demasiado grandes diluyen la pertinencia. Chunks demasiado pequeños pierden contexto. No existe un tamaño universal. Depende de tus documentos y tus consultas.
Los 5 errores de chunking más costosos
- Cortar una tabla por la mitad: una tabla dividida en dos produce chunks incomprensibles. Detecta tablas y mantenlas juntas.
- Demasiado solapamiento: 50% de overlap duplica el tamaño del índice sin mejorar la calidad. Apunta a 10-15%.
- Perder metadatos: título del capítulo, nombre del documento, fecha. Suelen desaparecer durante el chunking. Adjuntalos al chunk.
- Ignorar la estructura documental: dividir un documento jurídico por número de tokens ignora artículos y secciones. Usa la estructura lógica.
- Un solo formato para todo: un email de tres líneas y un informe de 200 páginas no se segmentan igual.
Contextual embedding: enriquecer cada chunk
Una técnica emergente mejora mucho la calidad del retrieval: contextual embedding. Antes de vectorizar un chunk, pide a un LLM que genere una frase corta que lo ubique en el contexto del documento completo. Esa frase se añade antes del embedding.
Resultado: cada chunk “sabe” de dónde viene. Un párrafo sobre especificaciones de una bomba X400 deja de ser un fragmento huérfano. Lleva contexto como “extracto del manual de mantenimiento de la bomba X400, capítulo de estanqueidad”. Aumenta la superficie semántica y el retrieval se vuelve más preciso.
2. Embedding
Cada chunk se transforma en un vector, una lista de números, normalmente entre 256 y 3.072 dimensiones, que codifica el significado semántico del texto. Dos frases con el mismo sentido tendrán vectores cercanos aunque usen palabras distintas.
Modelos de embedding usados en 2026:
| Modelo | Dimensiones | Proveedor | Nota |
|---|---|---|---|
text-embedding-3-small | 1.536 | OpenAI | Buena relación calidad/precio |
text-embedding-3-large | 3.072 | OpenAI | Más preciso, más caro |
embed-v4 | 1.024 | Cohere | Muy fuerte en multilingüe |
voyage-3-large | 1.024 | Voyage AI | Muy bueno en código y documentos técnicos |
voyage-multimodal-3 | 1.024 | Voyage AI | Texto + imágenes |
gemini-embedding-2 | 3.072 | Nuevo en marzo de 2026, multimodal nativo | |
mistral-embed | 1.024 | Mistral AI | Muy económico, correcto en retrieval general |
codestral-embed | 3.072 | Mistral AI | Especializado en código |
nomic-embed-text-v2-moe | 768 | Nomic AI | Open-source, Mixture of Experts |
gte-qwen2-instruct | 768-8192 | Alibaba | Open-source, dimensiones variables, buen multilingüe |
| BGE-M3, E5-Mistral, GTE | Variable | Comunidad | Gratuitos, autoalojados |
Importante: Gemini Embedding 2, lanzado en marzo de 2026, cambia el panorama. Puede colocar texto, imágenes, vídeo, audio y PDF en un mismo espacio vectorial. En la práctica, una búsqueda como “diagrama de cableado del conector X400” puede recuperar tanto un párrafo de documentación como una foto del conector.
Domina benchmarks MTEB en inglés, multilingüe y código, soporta más de 100 idiomas y usa Matryoshka Learning para truncar vectores con poca pérdida. Su límite: sigue en Public Preview y cuesta aproximadamente 50% más que OpenAI en uso solo texto. Para texto puro, las alternativas siguen siendo competitivas. Si tus documentos incluyen imágenes o diagramas, no tiene competidor directo.
3. Almacenamiento vectorial
Los vectores deben almacenarse en una base capaz de hacer búsqueda por similitud. Es la decisión arquitectónica central y la sección principal de este artículo.
4. Retrieval
Cuando un usuario hace una pregunta, la consulta también se transforma en vector y se compara con los vectores almacenados para encontrar chunks semánticamente cercanos.
La búsqueda vectorial pura tiene límites. Los sistemas modernos combinan:
- Búsqueda semántica: similitud vectorial;
- Búsqueda full-text: BM25 y palabras clave exactas, esencial para nombres, códigos de producto y referencias;
- Búsqueda híbrida: combinación ponderada de ambas;
- Reranking: un modelo especializado como Cohere Rerank o Jina Reranker reordena los resultados.
La búsqueda híbrida se ha convertido en el estándar de producción. La búsqueda vectorial pura falla con identificadores exactos, como “factura No.2024-0847”. La búsqueda full-text falla cuando la consulta se formula de forma distinta al documento.
Cómo funciona la búsqueda híbrida
El principio es simple: ejecutas dos búsquedas en paralelo, vectorial y BM25 full-text, y luego fusionas los resultados. El método más usado es Reciprocal Rank Fusion:
- La búsqueda vectorial devuelve un ranking: documento A primero, B tercero, C quinto.
- BM25 devuelve otro ranking: B primero, D segundo, A cuarto.
- RRF los combina ponderando el inverso del rango, con
knormalmente cerca de 60.
score = 1 / (k + rango_vectorial) + 1 / (k + rango_bm25)El documento B, bien posicionado en ambas búsquedas, sube a la cabeza.
Si un usuario busca “conector X400 resistente a humedad”, la búsqueda vectorial capta el sentido, por ejemplo “resistente a humedad” cercano a “estanco” o “IP67”, mientras BM25 captura el término exacto “X400”. Al combinar ambas, se recupera el documento correcto aunque la consulta mezcle lenguaje natural y términos técnicos.

4.5. Prompt engineering: la pieza invisible
Entre retrieval y generación, muchos equipos descuidan la construcción del prompt. Dedicar 80% del esfuerzo al retrieval y luego escribir un prompt básico es una receta para alucinaciones, incluso con buenos documentos en contexto.
Estructura el prompt en bloques separados:
- Sistema: rol de la IA, por ejemplo experto técnico, asistente jurídico o soporte cliente.
- Instrucciones: reglas estrictas, formato, longitud, tono y sobre todo grounding: “Responde solo a partir de los documentos proporcionados. Si la información no está en el contexto, dilo explícitamente.”
- Contexto: chunks recuperados con sus metadatos.
- Pregunta: consulta del usuario.
Tres técnicas que cambian el resultado:
- Citas obligatorias: exige que el LLM cite fuentes para cada afirmación. Reduce alucinaciones y permite verificación humana.
- Few-shot examples: proporciona 2 o 3 ejemplos completos de pregunta, razonamiento y respuesta esperada.
- Gestionar el lost in the middle: los LLM tienden a ignorar información en medio de contextos largos. Coloca los chunks más relevantes al inicio y al final.
5. Generación
Los chunks recuperados se inyectan en el prompt del LLM, que genera la respuesta final. La elección del LLM, GPT-4o, Claude, Gemini, Llama o Mistral, afecta la calidad de síntesis, pero suele ser la parte más fácil de cambiar.
Bases vectoriales: comparativa detallada

Aquí se decide la arquitectura más estructurante. Hay tres grandes familias.
Bases especializadas
Herramientas diseñadas desde el principio para almacenamiento y búsqueda vectorial.
Pinecone
- Despliegue: gestionado, serverless.
- Fortalezas: puesta en marcha rápida, sin infraestructura, escalado automático, búsqueda híbrida nativa, namespaces para multi-tenant.
- Debilidades: propietario, vendor lock-in, caro a escala, sin autoalojamiento, latencia variable.
- Mejor caso: equipos que quieren RAG en producción sin ops, scale-ups que priorizan time-to-market.
- Escala: miles de millones de vectores.
Qdrant
- Despliegue: self-hosted o Qdrant Cloud.
- Fortalezas: Rust, rápido, filtrado avanzado por metadatos, búsqueda híbrida, cuantización integrada, API simple.
- Debilidades: self-hosted requiere DevOps, la nube es más reciente que Pinecone.
- Mejor caso: equipos técnicos que quieren control y rendimiento, multi-cloud u on-premise.
Weaviate
- Despliegue: self-hosted o Weaviate Cloud.
- Fortalezas: API GraphQL, vectorización integrada, búsqueda híbrida BM25 + vectorial, módulos de generative search.
- Debilidades: más pesado que Qdrant, curva de GraphQL, posible acoplamiento.
- Mejor caso: proyectos que quieren un pipeline RAG integrado en la base.
Milvus / Zilliz
- Despliegue: Milvus autoalojado o Zilliz Cloud.
- Fortalezas: diseñado para escala masiva, separación storage/compute, GPU acceleration, muchos tipos de índices, proyecto CNCF.
- Debilidades: complejo de operar, varios componentes, excesivo para volúmenes pequeños.
- Mejor caso: volúmenes enormes, equipos DevOps, búsqueda multimodal.
ChromaDB
- Despliegue: embebido en Python o modo servidor.
- Fortalezas: instalación sencilla, API accesible, ideal para prototipos y notebooks.
- Debilidades: no está diseñado para producción a gran escala, sin búsqueda híbrida nativa, sin alta disponibilidad.
- Mejor caso: prototipos, POC, proyectos personales.
Turbopuffer
- Despliegue: serverless gestionado.
- Fortalezas: vectores sobre object storage, bajo coste en reposo, BM25 nativo, bueno para cargas variables.
- Debilidades: producto joven, latencia potencialmente mayor que bases en memoria, ecosistema pequeño.
- Mejor caso: corpus grandes consultados con poca frecuencia, archivo semántico, presupuesto ajustado.
Extensiones de bases existentes
¿Ya tienes una base de datos? Añade capacidades vectoriales.
pgvector (PostgreSQL)
- Despliegue: extensión PostgreSQL disponible en Supabase, Neon, AWS Aurora, Railway o PostgreSQL autoalojado.
- Fortalezas: no hay nueva base que operar, vectores junto a datos relacionales, SQL estándar, joins con tablas de negocio, híbrido con
tsvector+ pgvector. - Debilidades: menos rápido que bases especializadas por encima de 10M vectores, HNSW consume RAM.
- Mejor caso: pymes ya en PostgreSQL, proyectos donde los vectores deben cruzarse con datos de negocio.
Ejemplo: búsqueda semántica con pgvector
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title TEXT,
content TEXT,
embedding vector(1536)
);
CREATE INDEX ON documents
USING hnsw (embedding vector_cosine_ops);
SELECT title, content,
1 - (embedding <=> $1) AS similarity
FROM documents
ORDER BY embedding <=> $1
LIMIT 5;MongoDB Atlas Vector Search
Transparente si ya usas MongoDB Atlas. Combina búsqueda vectorial con filtrado de documentos y pipeline de agregación unificado. La contrapartida: solo Atlas y menos especialización que bases vectoriales dedicadas.
Redis Vector Search
Muy rápido porque trabaja en memoria. Útil para caché semántica o RAG de baja latencia en volúmenes moderados. El coste crece rápido con la RAM.
Cloudflare Vectorize
Gestionado e integrado con Cloudflare Workers. Bueno para equipos ya en el edge de Cloudflare, pero más limitado que bases especializadas.
Turso Vector
SQLite distribuido con soporte vectorial. Ligero, útil en edge, embedded o móvil, pero limitado para cargas vectoriales avanzadas.
Soluciones integradas en plataforma
Estas soluciones acoplan almacenamiento vectorial con una plataforma más amplia.
Convex (@convex-dev/rag)
- Despliegue: gestionado, integrado en Convex.
- Fortalezas: vectorial nativo en una base tiempo real, sin servicio separado, embeddings y búsqueda mediante funciones Convex, actualizaciones tiempo real, búsqueda híbrida, TypeScript end-to-end.
- Debilidades: acoplado a Convex, menos control sobre indexación que Qdrant o Milvus.
- Mejor caso: aplicaciones tiempo real que necesitan RAG sin complejidad de infraestructura.
Ejemplo: búsqueda semántica con Convex RAG
await rag.insertDocument(ctx, {
title: "Procedimiento de mantenimiento bomba X400",
body: "Para el mantenimiento trimestral de la bomba X400...",
metadata: { category: "maintenance", equipmentId: "X400" },
});
const results = await rag.search(ctx, {
query: "mantenimiento bomba entorno húmedo",
limit: 5,
filter: { category: "maintenance" },
});Firebase / Vertex AI RAG Engine
Gestionado en Google Cloud. Google se ocupa de ingesta, chunking, embedding, almacenamiento y retrieval, con integración Gemini y grounding con Google Search. Es potente si ya estás en Google Cloud, pero implica lock-in y pricing complejo.
OpenAI File Search
Gestionado por OpenAI. Subes archivos y obtienes RAG funcional en pocas líneas. La contrapartida: es una caja negra con poco control sobre chunking, embedding o retrieval, y el coste puede crecer con corpus grandes.
Frameworks RAG: la capa de orquestación
El almacenamiento vectorial es necesario, pero no suficiente. En producción hay que orquestar ingesta, chunking, retrieval, generación, errores, streaming y conversaciones multi-turno.
LangChain / LangGraph
El framework RAG más popular, en Python y JavaScript. Su fuerza es el ecosistema: conectores para casi todo, comunidad activa y LangSmith para monitoring. Sus debilidades son la abstracción excesiva, el debug difícil y los cambios de API. Es bueno para empezar; en producción muchos equipos usan solo algunos módulos.
LlamaIndex
Especializado en indexación y retrieval de documentos. Es más fuerte que LangChain para ingesta compleja, como PDF multicolumna, tablas o imágenes, y sus abstracciones de retriever están bien pensadas. Es menos generalista fuera de RAG.
Haystack
Framework RAG orientado a producción con pipelines declarativos. Menos vistoso, pero explícito y fiable, con buen soporte de evaluación.
RAGatouille
Biblioteca ligera centrada en ColBERT. Puede mejorar la calidad del retrieval sin cambiar toda la arquitectura, pero no es un framework completo.
Vercel AI SDK
SDK TypeScript/JavaScript para construir aplicaciones IA con soporte RAG. Encaja bien con React, Next.js y streaming, y es una buena opción para equipos TypeScript.
Soluciones llave en mano
Vertex AI RAG Engine y OpenAI File Search gestionan el pipeline: upload, indexación, consulta, respuesta. El time-to-market es excelente, pero el control es bajo, el lock-in alto y el coste puede crecer rápido.
Google Vertex AI & Grounding
Google ha tomado un enfoque específico que merece una sección propia.
Vertex AI Search
El grounding permite a Gemini verificar respuestas contra la web en tiempo real. Cuando Gemini genera una respuesta, puede consultar Google Search para confirmar hechos y añadir citas.
Es útil cuando tus datos propietarios deben completarse con información pública actual: noticias, regulación, datos de mercado.
Vertex AI RAG Engine
Un pipeline RAG completamente gestionado:
- Creas un corpus y subes documentos.
- Google gestiona parsing, chunking, embedding e indexación.
- Consultas vía API o directamente desde Gemini.
La promesa es cero infraestructura vectorial. La realidad: funciona bien para casos estándar, pero la falta de control sobre chunking y retrieval puede frustrar en documentos de negocio complejos.
Cuándo elegir Google
- Ya estás en Google Cloud.
- Gemini es tu LLM principal.
- Tus documentos son relativamente estándar.
- Necesitas mínimo time-to-market.
Cuándo construir tú mismo
- Necesitas control fino sobre chunking.
- Quieres ser agnóstico respecto al LLM.
- Tienes restricciones estrictas de latencia.
- Necesitas controlar con precisión la búsqueda híbrida.
Ir más allá: aspectos que se olvidan
Evaluar la calidad del RAG
Elegir una stack es una cosa. Saber si funciona es otra. En producción necesitas medir la calidad de las respuestas.
Frameworks de evaluación automática:
- RAGAS: mide fidelidad, pertinencia y completitud.
- DeepEval: añade métricas como alucinación, toxicidad y sesgo, con integración pytest.
- Haystack Evaluation: útil si ya usas Haystack.
Golden Dataset
Los frameworks de evaluación no sirven sin datos de referencia. Un Golden Dataset es una muestra de preguntas reales de usuarios, asociadas a respuestas esperadas y documentos fuente. Es una de las herramientas más infravaloradas y decisivas en un proyecto RAG.
Constrúyelo con expertos de negocio, no solo. Recoge preguntas reales de dificultad fácil, media y compleja. Define la respuesta esperada y el formato de salida. Para un prototipo bastan 10 a 50 preguntas. Para producción, apunta a 100-500.
Métricas a vigilar:
- Precisión: ¿la respuesta es exacta, completa y reproducible?
- Recall: ¿el retrieval encuentra los chunks correctos?
- Faithfulness: ¿la respuesta se mantiene anclada en las fuentes?
- Latencia: por encima de 3 a 5 segundos, el usuario abandona.
Cambia una sola variable cada vez y vuelve a ejecutar el Golden Dataset. Es la única forma de saber qué mejora o degrada la calidad.
RAG multimodal
En 2026, las empresas ya no buscan solo texto. Los técnicos necesitan diagramas técnicos, los analistas gráficos financieros, los equipos de formación vídeos.
El RAG multimodal aún es joven, pero emergen varias vías:
- ColPali / ColQwen: modelos de retrieval que trabajan directamente sobre imágenes de páginas, sin OCR.
- Milvus / Zilliz: soporte nativo de vectores multimodales.
- LLM multimodales: GPT-4o, Gemini y Claude pueden analizar imágenes en contexto RAG, pero recuperar las imágenes adecuadas sigue siendo el reto.
Si tus documentos de negocio contienen muchos visuales, lo multimodal ya no es un lujo. Espera un pipeline más complejo y costes de embedding más altos.
Privacidad y datos sensibles
Para empresas bajo RGPD o que manejan información sensible, la ingesta debe incluir detección y anonimización de PII antes del embedding.
En la práctica:
- Antes del embedding: escanear chunks para detectar nombres, emails, teléfonos, IBAN e identificadores sensibles.
- Anonimizar o seudonimizar: reemplazar PII por tokens genéricos antes de crear vectores.
- Herramientas: Microsoft Presidio, AWS Comprehend, spaCy con modelos NER propios.
Un vector de embedding contiene una representación semántica del texto. Teóricamente puede filtrar información sensible. La anonimización previa sigue siendo la protección más fiable.
Interfaz de usuario
La mayoría de guías RAG se detienen en el pipeline técnico. Sin embargo, la interfaz determina la adopción.
El chatbot clásico es una trampa. Una caja vacía con “Haz tu pregunta…” parece intuitiva. En la práctica, el usuario no siempre sabe qué preguntar, cómo formularlo ni qué contexto aportar. Resultado: preguntas vagas, respuestas imprecisas y pérdida de confianza.
La alternativa: interfaces de negocio guiadas. En lugar de una caja de texto, usa desplegables, campos estructurados y botones de selección. La interfaz captura 4 o 5 puntos de contexto y envía JSON estructurado al pipeline. El LLM devuelve una respuesta estructurada: síntomas, causas, soluciones, fuentes.
Por qué funciona:
- Menor carga cognitiva: el usuario no tiene que adivinar la formulación correcta.
- Mejor retrieval: una consulta estructurada con contexto de negocio tiene más superficie semántica.
- Orquestación por la UI: la interfaz puede enrutar hacia RAG, SQL o cálculo según las elecciones.
- Adopción: la calidad percibida depende tanto de la interfaz como del pipeline.
Experiencia de campo: Jonas Roman observa que la mayoría de proyectos RAG eficaces en producción no usan chatbots, sino interfaces de negocio dedicadas.
Observabilidad
Evaluar RAG antes del lanzamiento es necesario. En producción necesitas monitoring continuo.
Coloca puntos de control en cada etapa:
- Después del retrieval: ¿qué chunks se recuperaron? ¿Son pertinentes?
- Después del reranking: ¿cambió el orden? ¿Están los documentos correctos arriba?
- En la respuesta final: ¿cita fuentes? ¿Es fiel al contexto?
Cuando una respuesta es mala, estos checkpoints permiten hacer reverse engineering. ¿El retrieval trajo documentos equivocados? ¿El documento correcto estaba en contexto pero el LLM lo ignoró? ¿El prompt estaba mal estructurado?
Rechaza cajas negras en casos serios. RAG as a Service es cómodo para prototipos, pero ofrece poca visibilidad interna. En finanzas, salud o jurídico, la explicabilidad no es un extra. Es un requisito.
Más allá de los vectores
RAG no se limita a “embeddings + base vectorial”. Varias aproximaciones emergentes complementan o reemplazan la búsqueda semántica clásica.
GraphRAG / Knowledge Graphs
En lugar de dividir el texto y vectorizar chunks independientes, GraphRAG conserva relaciones y enlaces lógicos entre información. Es especialmente potente cuando necesitas exhaustividad: encontrar todos los contratos con una cláusula, trazar dependencias de procesos, identificar incumplimientos en un corpus.
Page Indexing
Técnica de RAG sin vectores que indexa documentos por página y estructura lógica. Útil cuando el layout del documento importa tanto como el contenido.
Agentes exploradores de File Search
Agentes que usan búsqueda multi-turno para leer datos como lo haría una persona. Lanzan una consulta inicial, analizan resultados, refinan la búsqueda e iteran.
Self-RAG / Reflective RAG
El sistema recupera información y luego verifica si es pertinente y suficiente. Si la calidad es baja, lanza nuevas consultas y solo responde tras superar sus propios criterios de fiabilidad.
Estas aproximaciones siguen siendo a menudo I+D. Conviene vigilarlas, pero con prudencia antes de producción. El RAG vectorial clásico con búsqueda híbrida sigue siendo el estándar probado.
Matriz de decisión
| Solución | Complejidad | Coste | Escalabilidad | Latencia | Híbrida | Multi-tenant | Open source | Madurez |
|---|---|---|---|---|---|---|---|---|
| Pinecone | Baja | Alto | 5/5 | 4/5 | Sí | Sí | No | 5/5 |
| Qdrant | Media | Bajo a medio | 5/5 | 5/5 | Sí | Sí | Sí | 4/5 |
| Weaviate | Media | Bajo a medio | 4/5 | 4/5 | Sí | Sí | Sí | 4/5 |
| Milvus | Alta | Bajo a medio | 5/5 | 5/5 | Sí | Sí | Sí | 4/5 |
| ChromaDB | Baja | Gratis | 2/5 | 3/5 | No | No | Sí | 2/5 |
| Turbopuffer | Baja | Bajo | 4/5 | 3/5 | Sí | Sí | No | 2/5 |
| pgvector | Baja | Bajo | 3/5 | 3/5 | Manual | Sí | Sí | 4/5 |
| MongoDB Atlas VS | Baja | Medio | 4/5 | 3/5 | No | Sí | No | 3/5 |
| Redis VS | Media | Medio | 3/5 | 5/5 | Sí | Sí | Sí | 3/5 |
| Convex RAG | Baja | Bajo a medio | 3/5 | 4/5 | Sí | Sí | SDK sí | 3/5 |
| Vertex AI RAG | Baja | Medio a alto | 5/5 | 3/5 | Sí | Sí | No | 3/5 |
| OpenAI File Search | Baja | Alto | 3/5 | 3/5 | No | No | No | 3/5 |
Recomendaciones por perfil
Startup early-stage
-> Convex (@convex-dev/rag) o pgvector vía Supabase
No tienes capacidad DevOps y quieres salir rápido. Convex ofrece base de datos, búsqueda vectorial y tiempo real en un servicio. Supabase + pgvector es la alternativa si prefieres PostgreSQL y tus necesidades vectoriales son simples.
No gastes tres meses diseñando el sistema RAG perfecto. Empieza simple e itera.
Pyme con PostgreSQL existente
-> pgvector
Ya tienes PostgreSQL en producción, un equipo que lo conoce y backups. Añade pgvector como migración SQL. Los vectores viven junto a tus datos de negocio.
Si superas 5 a 10 millones de vectores o la latencia se vuelve crítica, será momento de migrar a una base especializada.
Scale-up / gran volumen
-> Pinecone o Qdrant
Tienes decenas de millones de documentos, tráfico sostenido y requisitos de latencia. Pinecone si quieres cero ops. Qdrant si quieres control y tienes equipo para operarlo, o Qdrant Cloud.
Enterprise Google Cloud
-> Vertex AI RAG Engine + Qdrant/Pinecone para casos avanzados
Vertex AI cubre casos estándar. Qdrant o Pinecone cubren casos que requieren control fino. Google Search grounding es diferencial si los usuarios necesitan información pública actual.
Enterprise multi-cloud
-> Qdrant o Weaviate self-hosted
No quieres vendor lock-in. Qdrant y Weaviate corren en cualquier Kubernetes. Conservas control total sobre datos e infraestructura.
Prototipo rápido
-> ChromaDB u OpenAI File Search
Quieres validar una idea en una tarde. ChromaDB si usas Python y quieres entender la mecánica. OpenAI File Search si solo quieres ver RAG funcionando sin gestionar vectores.
No pongas ninguno de los dos en producción a gran escala.
Conclusión: RAG no es una única elección
RAG no es un producto que se compra. Es un espectro arquitectónico, desde “tres líneas de código con OpenAI File Search” hasta “pipeline distribuido con Qdrant, reranking Cohere y evaluación continua”.
La decisión correcta depende de tres factores:
- Dónde estás: prototipo, MVP o producción establecida.
- Qué tienes: equipo DevOps, PostgreSQL existente, Google Cloud.
- Qué necesitas: volumen, latencia, precisión.
El peor error es sobre-arquitectar. Las arquitecturas RAG multiagente parecen atractivas, pero la experiencia muestra que muchos sistemas demasiado ambiciosos no aguantan producción. Cada llamada LLM adicional multiplica la tasa de error. Si un modelo tiene 5% de error, encadenar varias llamadas reduce notablemente la fiabilidad global.
Empieza con la solución más simple que cubra la necesidad inmediata. pgvector o Convex para un primer RAG en producción. ChromaDB para un POC. Migra cuando, y solo cuando, alcances los límites.
El segundo peor error es subestimar el trabajo previo. La mejor base vectorial del mundo no compensa datos mal preparados, chunking inadecuado o un modelo de embedding mal elegido. La preparación de datos y la ingeniería de negocio representan la mayor parte del esfuerzo.
El tercer error suele ser invisible: descuidar la interfaz. Un RAG técnicamente sólido detrás de una caja de texto será infrautilizado. Piensa el RAG como un producto para usuarios de negocio, no solo como un pipeline técnico.
Una nota sobre tendencias: sigue de cerca arquitecturas sobre object storage como Turbopuffer, GraphRAG para casos que exigen exhaustividad y trazabilidad de relaciones, y Self-RAG para pipelines agentic más fiables. RAG no desaparece. Evoluciona hacia una infraestructura central de conocimiento para la IA empresarial.
¿Necesitas ayuda para elegir? En AppExpress implementamos sistemas RAG para pymes, desde un POC de una semana hasta pipelines de producción con evaluación continua. Si dudas entre opciones o quieres validar tu arquitectura antes de comprometerte, hablemos.