Qual sistema RAG escolher para seu aplicativo de negócio?

Introdução: RAG como espinha dorsal da IA aplicada
Você tem um catálogo de produtos com 50.000 referências. Um funcionário digita uma pergunta no chatbot interno: “Qual conector é compatível com a série X400 em ambiente úmido?” Um LLM clássico, mesmo GPT-4o ou Claude, não conhece seu catálogo. Ele vai gerar uma resposta plausível, mas errada.
O RAG (Retrieval-Augmented Generation) resolve esse problema. O princípio é simples: antes de deixar o LLM responder, o sistema busca os documentos relevantes nos seus dados e os injeta no contexto do modelo. O LLM responde com base nos seus dados reais, não apenas na memória de treinamento.
Em 2026, RAG se tornou difícil de ignorar porque os casos de uso se multiplicaram:
- Chatbot de suporte ao cliente: respostas baseadas em documentação, FAQ e tickets resolvidos;
- Busca documental interna: uma equipe jurídica procura um precedente em 10.000 contratos;
- Assistente de RH: funcionários perguntam sobre férias, benefícios e convenções coletivas;
- Base de conhecimento de produto: técnicos de campo buscam procedimentos de manutenção;
- Análise regulatória: LGPD/RGPD, normas ISO, textos legais.
O ponto comum é claro: você possui dados proprietários e quer que um LLM os use de forma inteligente. Não é necessário fazer fine-tuning do modelo sempre que um documento muda. RAG trabalha sobre dados vivos.
Mas entre Pinecone, pgvector, Qdrant, LangChain, Vertex AI e muitas outras opções, a escolha ficou confusa. Este guia ajuda a entender os trade-offs.
Antes de escolher uma stack: a auditoria de dados esquecida
Antes de comparar bancos vetoriais ou escolher um framework, existe uma etapa que a maioria dos projetos RAG pula. Ela também é a primeira causa de fracasso.
Como explica Jonas Roman, profissional de RAG com mais de 60 projetos em produção: 70 a 80% do trabalho de um projeto RAG está na preparação dos dados, não em prompts, modelos ou arquitetura. É o clássico garbage in, garbage out. Nenhum banco vetorial, por mais poderoso que seja, compensa dados mal preparados.
Antes de escrever código, audite seus dados em quatro dimensões:
- Qualidade: os documentos são legíveis? PDFs escaneados são utilizáveis? Para documentos complexos, como diagramas e tabelas, ferramentas OCR avançadas como Mistral OCR geram resultados melhores que extratores básicos.
- Estrutura: os dados são homogêneos? Emails de três linhas misturados com relatórios de 200 páginas, formatos incoerentes e informações contraditórias precisam ser mapeados desde o início.
- Completude: você realmente tem todos os dados necessários? É comum as equipes de negócio acreditarem que tudo está disponível, mas ninguém verificou. No meio do projeto, uma parte importante pode se mostrar inutilizável.
- Acessibilidade: onde os dados vivem? Documentos não estruturados, bancos SQL, ERP, CRM. Esse mapa determina a arquitetura alvo.
Conselho prático: algumas horas de alinhamento com especialistas de negócio podem evitar semanas de desenvolvimento na direção errada. Invista esse tempo antes da primeira linha de código.
Quando RAG não é a resposta
O reflexo “dados internos = RAG vetorial” se tornou automático. Mas RAG clássico, embeddings mais busca semântica, nem sempre é a ferramenta certa. Antes de implementar, faça estas perguntas.
A resposta já existe em dados estruturados?
Se a pergunta é “Qual foi o faturamento por região em 2023?” e o dado vive em um ERP ou banco SQL, você não precisa de RAG. Uma consulta SQL direta será mais confiável, rápida e barata. RAG recupera trechos de texto; não agrega, não calcula e não garante exatidão numérica.
É preciso percorrer todo o corpus?
“Quais são os principais aprendizados dos nossos 30 relatórios de auditoria de 2024?” RAG foi feito para encontrar os trechos mais relevantes, não para ler uma biblioteca inteira. Para análises globais, use abordagens map-reduce, resumindo cada documento e depois sintetizando os resumos, ou um processamento multipass.
Você precisa de exaustividade?
“Liste todos os contratos com cláusula de não concorrência.” Em 200 contratos, um RAG vetorial pode encontrar 40 de 47. Os 7 restantes passam despercebidos. Em contexto jurídico ou regulatório, essa lacuna é inaceitável. Para esses casos, você precisa de Knowledge Graphs ou busca híbrida reforçada.
Há cálculos a fazer?
RAG não calcula. Se a resposta exige operações aritméticas sobre dados, crie tools dedicadas, como funções de cálculo ou chamadas API, que o LLM possa acionar fora do pipeline RAG.
Bons sistemas quase sempre são híbridos. Um classificador LLM antes do pipeline analisa a intenção e roteia a solicitação para a ferramenta adequada: RAG vetorial para compreensão semântica, SQL para dados estruturados, tools para cálculos, map-reduce para sínteses globais. Esse roteador pode ser apenas um LLM classificando a pergunta em poucos segundos.
As peças do RAG
Um sistema RAG não é uma única ferramenta. É um pipeline composto por cinco etapas distintas, cada uma com suas próprias decisões tecnológicas.
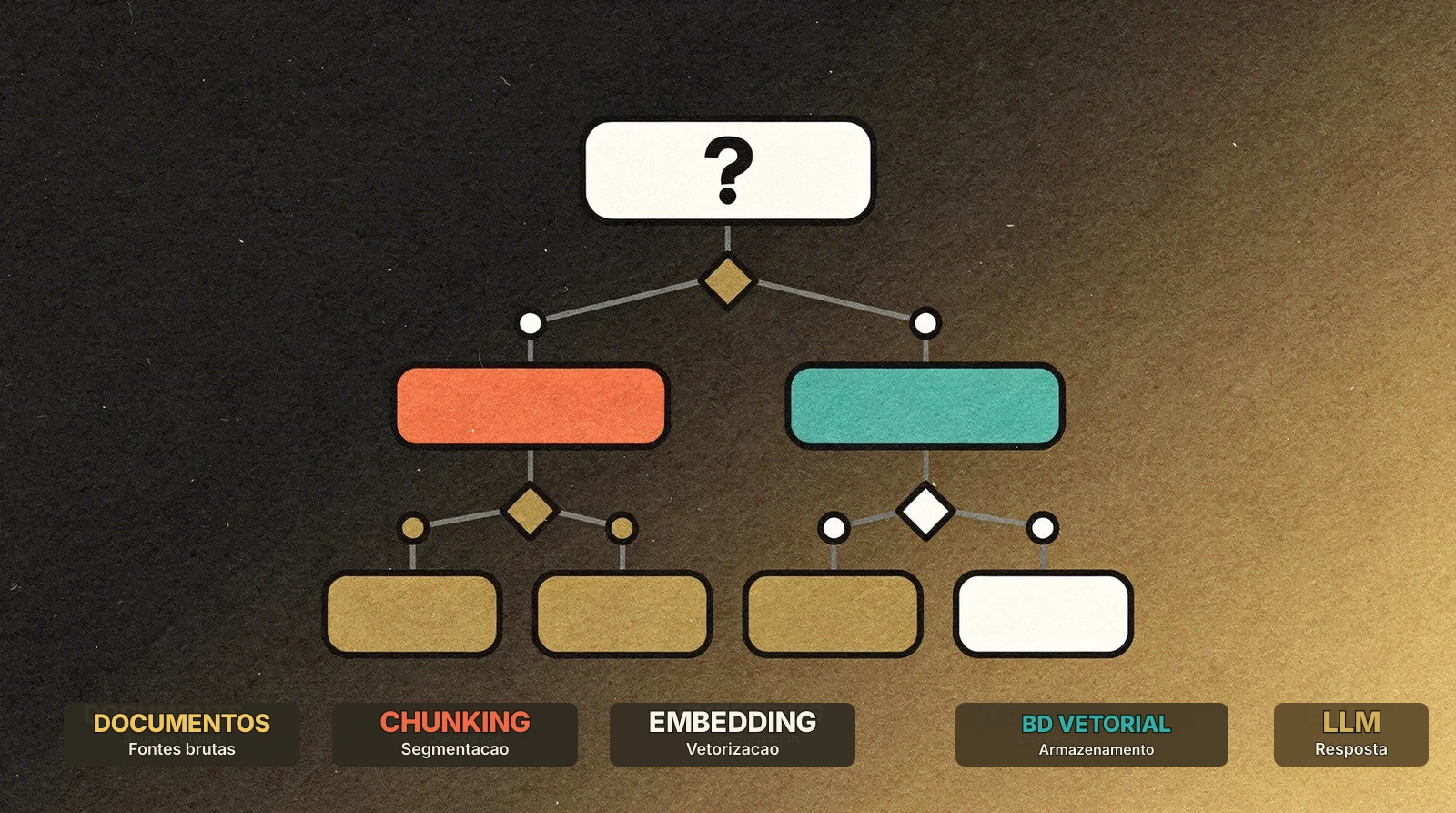
1. Ingestão
Documentos brutos, sejam PDFs, páginas web, emails, arquivos Word ou dados SQL, precisam ser transformados em partes utilizáveis. É a etapa de parsing e chunking.
- Parsing: extrair texto de um PDF escaneado, interpretar uma tabela HTML, limpar Markdown;
- Chunking: dividir um documento de 200 páginas em segmentos de 500 a 1.500 tokens, com ou sem sobreposição.
Chunking é mais crítico do que parece. Chunks grandes demais diluem relevância. Chunks pequenos demais perdem contexto. Não existe tamanho universal. Depende dos documentos e das consultas.
Os 5 erros de chunking mais caros
- Cortar uma tabela ao meio: uma tabela dividida em dois gera chunks incompreensíveis. Detecte tabelas e mantenha-as juntas.
- Sobreposição grande demais: 50% de overlap duplica o índice sem melhorar qualidade. Mire 10 a 15%.
- Perder metadados: título do capítulo, nome do documento, data. Eles costumam desaparecer durante o chunking. Anexe-os ao chunk.
- Ignorar a estrutura do documento: dividir um documento jurídico por número de tokens ignora artigos e seções. Use a estrutura lógica.
- Um formato único para tudo: um email de três linhas e um relatório de 200 páginas não devem ser segmentados da mesma forma.
Contextual embedding: enriquecer cada chunk
Uma técnica emergente melhora muito a qualidade do retrieval: contextual embedding. Antes de vetorizar um chunk, peça a um LLM que gere uma frase curta situando o chunk no contexto do documento completo. Essa frase é adicionada antes do embedding.
Resultado: cada chunk “sabe” de onde vem. Um parágrafo sobre especificações de uma bomba X400 deixa de ser um fragmento órfão. Ele carrega contexto como “trecho do manual de manutenção da bomba X400, capítulo de vedação”. A superfície semântica aumenta e o retrieval fica mais preciso.
2. Embedding
Cada chunk vira um vetor, uma lista de números, normalmente entre 256 e 3.072 dimensões, que codifica o significado semântico do texto. Duas frases com o mesmo sentido terão vetores próximos, mesmo com palavras diferentes.
Modelos de embedding usados em 2026:
| Modelo | Dimensões | Fornecedor | Nota |
|---|---|---|---|
text-embedding-3-small | 1.536 | OpenAI | Boa relação custo/qualidade |
text-embedding-3-large | 3.072 | OpenAI | Mais preciso, mais caro |
embed-v4 | 1.024 | Cohere | Muito forte em multilingue |
voyage-3-large | 1.024 | Voyage AI | Muito bom em código e documentos técnicos |
voyage-multimodal-3 | 1.024 | Voyage AI | Texto + imagens |
gemini-embedding-2 | 3.072 | Novo em março de 2026, multimodal nativo | |
mistral-embed | 1.024 | Mistral AI | Muito econômico, correto em retrieval geral |
codestral-embed | 3.072 | Mistral AI | Especializado em código |
nomic-embed-text-v2-moe | 768 | Nomic AI | Open-source, Mixture of Experts |
gte-qwen2-instruct | 768-8192 | Alibaba | Open-source, dimensões variáveis, bom multilingue |
| BGE-M3, E5-Mistral, GTE | Variável | Comunidade | Gratuitos, auto-hospedados |
Importante: Gemini Embedding 2, lançado em março de 2026, muda o cenário. Ele coloca texto, imagens, vídeo, áudio e PDFs no mesmo espaço vetorial. Na prática, uma busca por “diagrama de fiação do conector X400” pode recuperar tanto um parágrafo de documentação quanto uma foto do conector.
Ele lidera benchmarks MTEB em inglês, multilingue e código, suporta mais de 100 idiomas e usa Matryoshka Learning para truncar vetores com pouca perda. O limite: ainda está em Public Preview e custa cerca de 50% mais que OpenAI para uso somente texto. Para texto puro, as alternativas continuam competitivas. Se seus documentos têm imagens ou diagramas, ele não tem concorrente direto.
3. Armazenamento vetorial
Vetores precisam ser armazenados em uma base capaz de fazer busca por similaridade. Esta é a decisão arquitetural central e a principal seção deste artigo.
4. Retrieval
Quando o usuário faz uma pergunta, a consulta também vira um vetor e é comparada aos vetores armazenados para encontrar chunks semanticamente próximos.
A busca vetorial pura tem limites. Sistemas modernos combinam:
- Busca semântica: similaridade vetorial;
- Busca full-text: BM25 e palavras-chave exatas, essencial para nomes, códigos de produto e referências;
- Busca híbrida: combinação ponderada das duas;
- Reranking: um modelo especializado como Cohere Rerank ou Jina Reranker reordena resultados.
A busca híbrida se tornou o padrão em produção. A busca vetorial pura falha com identificadores exatos, como “fatura No.2024-0847”. A busca full-text falha quando a consulta é formulada de modo diferente do documento.
Como a busca híbrida funciona
O princípio é simples: executar duas buscas em paralelo, vetorial e BM25 full-text, e depois fundir os resultados. O método mais usado é Reciprocal Rank Fusion:
- A busca vetorial retorna um ranking: documento A primeiro, B terceiro, C quinto.
- BM25 retorna outro ranking: B primeiro, D segundo, A quarto.
- RRF combina os dois ponderando o inverso da posição, com
kgeralmente perto de 60.
score = 1 / (k + ranking_vetorial) + 1 / (k + ranking_bm25)O documento B, bem posicionado nas duas buscas, sobe para o topo.
Se o usuário busca “conector X400 resistente à umidade”, a busca vetorial capta o sentido, por exemplo “resistente à umidade” próximo de “vedado” ou “IP67”, enquanto BM25 captura o termo exato “X400”. Combinando ambos, você encontra o documento certo mesmo quando a consulta mistura linguagem natural e termos técnicos.

4.5. Prompt engineering: a peça invisível
Entre retrieval e geração, muitas equipes negligenciam a construção do prompt. Gastar 80% do esforço no retrieval e depois escrever um prompt básico é uma receita para alucinações, mesmo com bons documentos em contexto.
Estruture o prompt em blocos separados:
- Sistema: papel da IA, como especialista técnico, assistente jurídico ou suporte ao cliente.
- Instruções: regras estritas, formato, tamanho, tom e principalmente grounding: “Responda apenas com base nos documentos fornecidos. Se a informação não estiver no contexto, diga explicitamente.”
- Contexto: chunks recuperados, com metadados.
- Pergunta: consulta do usuário.
Três técnicas que mudam o resultado:
- Citações obrigatórias: exija que o LLM cite fontes para cada afirmação. Isso reduz alucinações e permite verificação humana.
- Few-shot examples: forneça 2 ou 3 exemplos completos de pergunta, raciocínio e resposta esperada.
- Gerenciar o lost in the middle: LLMs tendem a ignorar informações no meio de contextos longos. Coloque os chunks mais relevantes no início e no fim.
5. Geração
Os chunks recuperados são injetados no prompt do LLM, que gera a resposta final. A escolha do LLM, GPT-4o, Claude, Gemini, Llama ou Mistral, afeta a qualidade da síntese, mas costuma ser a parte mais simples de trocar.
Bancos vetoriais: comparação detalhada

Aqui acontece a decisão arquitetural mais estruturante. Existem três grandes famílias.
Bancos especializados
Ferramentas projetadas desde o início para armazenamento e busca vetorial.
Pinecone
- Deploy: gerenciado, serverless.
- Forças: configuração rápida, sem infraestrutura, escala automática, busca híbrida nativa, namespaces para multi-tenant.
- Fraquezas: proprietário, vendor lock-in, caro em escala, sem auto-hospedagem, latência variável.
- Melhor caso: equipes que querem RAG em produção sem ops, scale-ups que priorizam time-to-market.
- Escala: bilhões de vetores.
Qdrant
- Deploy: self-hosted ou Qdrant Cloud.
- Forças: Rust, rápido, filtros avançados por metadados, busca híbrida, quantização integrada, API simples.
- Fraquezas: self-hosted exige DevOps, nuvem mais recente que Pinecone.
- Melhor caso: equipes técnicas que querem controle e desempenho, multi-cloud ou on-premise.
Weaviate
- Deploy: self-hosted ou Weaviate Cloud.
- Forças: API GraphQL, vetorização integrada, busca híbrida BM25 + vetorial, módulos de generative search.
- Fraquezas: mais pesado que Qdrant, curva GraphQL, possível acoplamento.
- Melhor caso: projetos que querem pipeline RAG integrado na base.
Milvus / Zilliz
- Deploy: Milvus auto-hospedado ou Zilliz Cloud.
- Forças: feito para escala massiva, separação storage/compute, GPU acceleration, muitos tipos de índice, projeto CNCF.
- Fraquezas: complexo de operar, vários componentes, exagerado para volumes pequenos.
- Melhor caso: volumes enormes, equipes DevOps, busca multimodal.
ChromaDB
- Deploy: embutido em Python ou modo servidor.
- Forças: instalação simples, API acessível, ótimo para protótipos e notebooks.
- Fraquezas: não foi feito para produção em larga escala, sem busca híbrida nativa, sem alta disponibilidade.
- Melhor caso: protótipos, POCs, projetos pessoais.
Turbopuffer
- Deploy: serverless gerenciado.
- Forças: vetores em object storage, baixo custo em repouso, BM25 nativo, bom para cargas variáveis.
- Fraquezas: produto jovem, latência possivelmente maior que bases em memória, ecossistema pequeno.
- Melhor caso: corpus grandes consultados raramente, arquivo semântico, orçamento apertado.
Extensões de bancos existentes
Já tem um banco de dados? Adicione capacidades vetoriais.
pgvector (PostgreSQL)
- Deploy: extensão PostgreSQL disponível em Supabase, Neon, AWS Aurora, Railway ou PostgreSQL auto-hospedado.
- Forças: sem novo banco para operar, vetores junto dos dados relacionais, SQL padrão, joins com tabelas de negócio, híbrido com
tsvector+ pgvector. - Fraquezas: menos rápido que bancos especializados acima de 10M vetores, HNSW consome RAM.
- Melhor caso: PMEs já em PostgreSQL, projetos onde vetores precisam cruzar dados de negócio.
Exemplo: busca semântica com pgvector
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title TEXT,
content TEXT,
embedding vector(1536)
);
CREATE INDEX ON documents
USING hnsw (embedding vector_cosine_ops);
SELECT title, content,
1 - (embedding <=> $1) AS similarity
FROM documents
ORDER BY embedding <=> $1
LIMIT 5;MongoDB Atlas Vector Search
Transparente se você já usa MongoDB Atlas. Combina busca vetorial com filtro em documentos e pipeline de agregação unificado. A contrapartida: apenas Atlas e menos especialização que bancos vetoriais dedicados.
Redis Vector Search
Muito rápido porque trabalha em memória. Útil para cache semântico ou RAG de baixa latência em volumes moderados. O custo cresce rapidamente com RAM.
Cloudflare Vectorize
Gerenciado e integrado ao Cloudflare Workers. Bom para equipes já no edge Cloudflare, mas mais limitado que bancos especializados.
Turso Vector
SQLite distribuído com suporte vetorial. Leve, útil em edge, embedded ou mobile, mas limitado para cargas vetoriais avançadas.
Soluções integradas em plataforma
Essas soluções acoplam armazenamento vetorial com uma plataforma mais ampla.
Convex (@convex-dev/rag)
- Deploy: gerenciado, integrado ao Convex.
- Forças: vetorial nativo em banco em tempo real, sem serviço separado, embeddings e busca via funções Convex, atualizações em tempo real, busca híbrida, TypeScript end-to-end.
- Fraquezas: acoplado ao Convex, menos controle de indexação que Qdrant ou Milvus.
- Melhor caso: aplicações em tempo real que precisam de RAG sem complexidade de infraestrutura.
Exemplo: busca semântica com Convex RAG
await rag.insertDocument(ctx, {
title: "Procedimento de manutenção bomba X400",
body: "Para a manutenção trimestral da bomba X400...",
metadata: { category: "maintenance", equipmentId: "X400" },
});
const results = await rag.search(ctx, {
query: "manutenção bomba ambiente úmido",
limit: 5,
filter: { category: "maintenance" },
});Firebase / Vertex AI RAG Engine
Gerenciado no Google Cloud. O Google cuida de ingestão, chunking, embedding, armazenamento e retrieval, com integração Gemini e grounding com Google Search. É forte para quem já está no Google Cloud, mas envolve lock-in e pricing complexo.
OpenAI File Search
Gerenciado pela OpenAI. Você sobe arquivos e obtém RAG funcional em poucas linhas. A contrapartida: é uma caixa preta com pouco controle sobre chunking, embedding ou retrieval, e o custo pode crescer com grandes corpus.
Frameworks RAG: camada de orquestração
Armazenamento vetorial é necessário, mas não suficiente. Em produção, é preciso orquestrar ingestão, chunking, retrieval, geração, erros, streaming e conversas multi-turn.
LangChain / LangGraph
O framework RAG mais popular, em Python e JavaScript. Sua força é o ecossistema: conectores para quase tudo, comunidade ativa e LangSmith para monitoring. Suas fraquezas são abstração excessiva, debug difícil e mudanças frequentes de API. É bom para começar; em produção, muitas equipes usam apenas alguns módulos.
LlamaIndex
Especializado em indexação e retrieval de documentos. É mais forte que LangChain em ingestão complexa, como PDFs multicoluna, tabelas e imagens, e suas abstrações de retriever são bem pensadas. É menos generalista fora de RAG.
Haystack
Framework RAG orientado a produção com pipelines declarativos. Menos chamativo, mas explícito e confiável, com bom suporte a avaliação.
RAGatouille
Biblioteca leve centrada em ColBERT. Pode melhorar a qualidade do retrieval sem trocar toda a arquitetura, mas não é um framework completo.
Vercel AI SDK
SDK TypeScript/JavaScript para criar aplicações de IA com suporte RAG. Encaixa bem com React, Next.js e streaming, e é uma boa escolha para equipes TypeScript.
Soluções prontas
Vertex AI RAG Engine e OpenAI File Search gerenciam o pipeline: upload, indexação, consulta, resposta. O time-to-market é excelente, mas o controle é baixo, o lock-in alto e o custo pode crescer rápido.
Google Vertex AI & Grounding
O Google adotou uma abordagem específica que merece uma seção própria.
Vertex AI Search
Grounding permite que Gemini verifique respostas contra a web em tempo real. Ao gerar uma resposta, Gemini pode consultar Google Search para confirmar fatos e adicionar citações.
Isso é útil quando dados proprietários precisam ser enriquecidos com informação pública atual: notícias, regulação, dados de mercado.
Vertex AI RAG Engine
Um pipeline RAG totalmente gerenciado:
- Você cria um corpus e envia documentos.
- Google gerencia parsing, chunking, embedding e indexação.
- Você consulta via API ou diretamente pelo Gemini.
A promessa é zero infraestrutura vetorial. A realidade: funciona bem para casos padrão, mas a falta de controle sobre chunking e retrieval pode frustrar em documentos de negócio complexos.
Quando escolher Google
- Você já está no Google Cloud.
- Gemini é seu LLM principal.
- Seus documentos são relativamente padrão.
- Você precisa de mínimo time-to-market.
Quando construir você mesmo
- Você precisa de controle fino sobre chunking.
- Quer ser agnóstico em relação ao LLM.
- Tem restrições rígidas de latência.
- Precisa controlar a busca híbrida com precisão.
Indo além: aspectos esquecidos
Avaliar a qualidade do RAG
Escolher uma stack é uma coisa. Saber se ela funciona é outra. Em produção, você precisa medir a qualidade das respostas.
Frameworks de avaliação automática:
- RAGAS: mede fidelidade, relevância e completude.
- DeepEval: adiciona métricas como alucinação, toxicidade e viés, com integração pytest.
- Haystack Evaluation: útil se você já usa Haystack.
Golden Dataset
Frameworks de avaliação não servem sem dados de referência. Um Golden Dataset é uma amostra de perguntas reais dos usuários, associadas a respostas esperadas e documentos fonte. É uma das ferramentas mais subestimadas e decisivas em um projeto RAG.
Construa com especialistas de negócio, não sozinho. Colete perguntas reais de dificuldade fácil, média e complexa. Defina a resposta esperada e o formato de saída. Para um protótipo, 10 a 50 perguntas bastam. Para produção, mire 100 a 500.
Métricas a acompanhar:
- Precisão: a resposta é exata, completa e reproduzível?
- Recall: o retrieval encontra os chunks corretos?
- Faithfulness: a resposta permanece ancorada nas fontes?
- Latência: acima de 3 a 5 segundos, o usuário abandona.
Mude apenas uma variável por vez e rode novamente o Golden Dataset. É a única forma de saber o que melhora ou degrada a qualidade.
RAG multimodal
Em 2026, empresas já não buscam apenas texto. Técnicos precisam de diagramas técnicos, analistas de gráficos financeiros, equipes de treinamento de vídeos.
RAG multimodal ainda é jovem, mas algumas vias emergem:
- ColPali / ColQwen: modelos de retrieval que trabalham diretamente em imagens de páginas, sem OCR.
- Milvus / Zilliz: suporte nativo a vetores multimodais.
- LLMs multimodais: GPT-4o, Gemini e Claude analisam imagens em contexto RAG, mas recuperar as imagens certas continua sendo o desafio.
Se seus documentos de negócio contêm muitos visuais, multimodal já não é luxo. Espere um pipeline mais complexo e custos de embedding maiores.
Privacidade e dados sensíveis
Para empresas sob LGPD/RGPD ou que lidam com informação sensível, a ingestão deve incluir detecção e anonimização de PII antes do embedding.
Na prática:
- Antes do embedding: escanear chunks para detectar nomes, emails, telefones, IBANs e identificadores sensíveis.
- Anonimizar ou pseudonimizar: substituir PII por tokens genéricos antes de criar vetores.
- Ferramentas: Microsoft Presidio, AWS Comprehend, spaCy com modelos NER próprios.
Um vetor de embedding contém uma representação semântica do texto. Informações sensíveis podem teoricamente vazar dele. A anonimização prévia continua sendo a proteção mais confiável.
Interface de usuário
A maioria dos guias RAG para no pipeline técnico. No entanto, é a interface que determina a adoção.
O chatbot clássico é uma armadilha. Uma caixa vazia com “Faça sua pergunta…” parece intuitiva. Na prática, o usuário nem sempre sabe o que perguntar, como formular ou que contexto fornecer. Resultado: perguntas vagas, respostas imprecisas e perda de confiança.
A alternativa: interfaces de negócio guiadas. Em vez de uma caixa de texto, use menus, campos estruturados e botões de seleção. A interface captura 4 ou 5 pontos de contexto e envia JSON estruturado ao pipeline. O LLM devolve resposta estruturada: sintomas, causas, soluções, fontes.
Por que funciona:
- Menor carga cognitiva: o usuário não precisa adivinhar a formulação correta.
- Melhor retrieval: uma consulta estruturada com contexto de negócio tem mais superfície semântica.
- Orquestração pela UI: a interface pode rotear para RAG, SQL ou cálculo conforme as escolhas.
- Adoção: a qualidade percebida depende tanto da interface quanto do pipeline.
Experiência de campo: Jonas Roman observa que a maioria dos projetos RAG eficazes em produção não usa chatbots, mas interfaces de negócio dedicadas.
Observabilidade
Avaliar RAG antes do lançamento é necessário. Em produção, você precisa de monitoramento contínuo.
Coloque pontos de controle em cada etapa:
- Após o retrieval: quais chunks foram recuperados? São relevantes?
- Após o reranking: a ordem mudou? Os documentos certos estão no topo?
- Na resposta final: há citações? A resposta é fiel ao contexto?
Quando uma resposta é ruim, esses checkpoints permitem fazer reverse engineering. O retrieval trouxe documentos errados? O documento correto estava no contexto mas o LLM ignorou? O prompt estava mal estruturado?
Rejeite caixas pretas em casos sérios. RAG as a Service é prático para protótipos, mas oferece pouca visibilidade interna. Em finanças, saúde ou jurídico, explicabilidade não é extra. É requisito.
Além dos vetores
RAG não se limita a “embeddings + banco vetorial”. Várias abordagens emergentes complementam ou substituem a busca semântica clássica.
GraphRAG / Knowledge Graphs
Em vez de dividir texto e vetorizar chunks independentes, GraphRAG preserva relações e links lógicos entre informações. É especialmente poderoso quando você precisa de exaustividade: encontrar todos os contratos com uma cláusula, rastrear dependências de processos, identificar não conformidades em um corpus.
Page Indexing
Técnica de RAG sem vetores que indexa documentos por página e estrutura lógica. Útil quando o layout carrega tanto sentido quanto o conteúdo.
Agentes exploradores de File Search
Agentes que usam busca multi-turn para ler dados como uma pessoa faria. Lançam uma consulta inicial, analisam resultados, refinam a busca e iteram.
Self-RAG / Reflective RAG
O sistema recupera informações e depois verifica se são relevantes e suficientes. Se a qualidade for baixa, lança novas consultas e só responde após passar seus próprios critérios de confiabilidade.
Essas abordagens ainda costumam estar em P&D. Vale acompanhar, mas com prudência antes de produção. O RAG vetorial clássico com busca híbrida continua sendo o padrão comprovado.
Matriz de decisão
| Solução | Complexidade | Custo | Escalabilidade | Latência | Híbrida | Multi-tenant | Open source | Maturidade |
|---|---|---|---|---|---|---|---|---|
| Pinecone | Baixa | Alto | 5/5 | 4/5 | Sim | Sim | Não | 5/5 |
| Qdrant | Média | Baixo a médio | 5/5 | 5/5 | Sim | Sim | Sim | 4/5 |
| Weaviate | Média | Baixo a médio | 4/5 | 4/5 | Sim | Sim | Sim | 4/5 |
| Milvus | Alta | Baixo a médio | 5/5 | 5/5 | Sim | Sim | Sim | 4/5 |
| ChromaDB | Baixa | Grátis | 2/5 | 3/5 | Não | Não | Sim | 2/5 |
| Turbopuffer | Baixa | Baixo | 4/5 | 3/5 | Sim | Sim | Não | 2/5 |
| pgvector | Baixa | Baixo | 3/5 | 3/5 | Manual | Sim | Sim | 4/5 |
| MongoDB Atlas VS | Baixa | Médio | 4/5 | 3/5 | Não | Sim | Não | 3/5 |
| Redis VS | Média | Médio | 3/5 | 5/5 | Sim | Sim | Sim | 3/5 |
| Convex RAG | Baixa | Baixo a médio | 3/5 | 4/5 | Sim | Sim | SDK sim | 3/5 |
| Vertex AI RAG | Baixa | Médio a alto | 5/5 | 3/5 | Sim | Sim | Não | 3/5 |
| OpenAI File Search | Baixa | Alto | 3/5 | 3/5 | Não | Não | Não | 3/5 |
Recomendações por perfil
Startup early-stage
-> Convex (@convex-dev/rag) ou pgvector via Supabase
Você não tem capacidade DevOps e quer lançar rápido. Convex oferece banco, busca vetorial e tempo real em um serviço. Supabase + pgvector é a alternativa se você prefere PostgreSQL e suas necessidades vetoriais são simples.
Não gaste três meses desenhando o sistema RAG perfeito. Comece simples e itere.
PME com PostgreSQL existente
-> pgvector
Você já tem PostgreSQL em produção, uma equipe que conhece e backups. Adicione pgvector como migração SQL. Os vetores vivem junto aos dados de negócio.
Se passar de 5 a 10 milhões de vetores ou a latência se tornar crítica, será hora de migrar para um banco especializado.
Scale-up / grande volume
-> Pinecone ou Qdrant
Você tem dezenas de milhões de documentos, tráfego sustentado e requisitos de latência. Pinecone se quiser zero ops. Qdrant se quiser controle e tiver equipe para operar, ou Qdrant Cloud.
Enterprise Google Cloud
-> Vertex AI RAG Engine + Qdrant/Pinecone para casos avançados
Vertex AI cobre casos padrão. Qdrant ou Pinecone cobrem casos que exigem controle fino. Google Search grounding é diferencial se usuários precisam de informação pública atual.
Enterprise multi-cloud
-> Qdrant ou Weaviate self-hosted
Você não quer vendor lock-in. Qdrant e Weaviate rodam em qualquer Kubernetes. Você mantém controle total sobre dados e infraestrutura.
Protótipo rápido
-> ChromaDB ou OpenAI File Search
Você quer validar uma ideia em uma tarde. ChromaDB se usa Python e quer entender a mecânica. OpenAI File Search se só quer ver RAG funcionando sem gerenciar vetores.
Não coloque nenhum dos dois em produção em larga escala.
Conclusão: RAG não é uma única escolha
RAG não é um produto que se compra. É um espectro arquitetural, de “três linhas de código com OpenAI File Search” a “pipeline distribuído com Qdrant, reranking Cohere e avaliação contínua”.
A escolha certa depende de três fatores:
- Onde você está: protótipo, MVP ou produção estabelecida.
- O que você tem: equipe DevOps, PostgreSQL existente, Google Cloud.
- O que você precisa: volume, latência, precisão.
O pior erro é sobre-arquitetar. Arquiteturas RAG multiagente parecem atraentes, mas a experiência mostra que muitos sistemas ambiciosos demais não se sustentam em produção. Cada chamada LLM adicional multiplica a taxa de erro. Se um modelo tem 5% de erro, encadear várias chamadas reduz bastante a confiabilidade global.
Comece com a solução mais simples que resolve a necessidade imediata. pgvector ou Convex para um primeiro RAG em produção. ChromaDB para um POC. Migre quando, e somente quando, alcançar os limites.
O segundo pior erro é subestimar o trabalho prévio. O melhor banco vetorial do mundo não compensa dados mal preparados, chunking inadequado ou modelo de embedding mal escolhido. Preparação de dados e engenharia de negócio representam a maior parte do esforço.
O terceiro erro costuma ser invisível: negligenciar a interface. Um RAG tecnicamente sólido atrás de uma caixa de texto será subutilizado. Pense em RAG como produto para usuários de negócio, não apenas como pipeline técnico.
Uma nota sobre tendências: acompanhe arquiteturas sobre object storage como Turbopuffer, GraphRAG para casos que exigem exaustividade e rastreabilidade de relações, e Self-RAG para pipelines agentic mais confiáveis. RAG não está desaparecendo. Ele evolui para uma infraestrutura central de conhecimento para IA empresarial.
Precisa de ajuda para escolher? Na AppExpress, implementamos sistemas RAG para PMEs, de um POC em uma semana a pipelines de produção com avaliação contínua. Se você está em dúvida entre opções ou quer validar sua arquitetura antes de se comprometer, vamos conversar.